理解指标类型
Prometheus 支持四种类型的指标,它们分别是:
- Counter(计数器)
- Gauge(测量值)
- Histogram(测量值)
- Summary(汇总)
Counter
Counter 是一种只能增加或重置的指标值,其值不能低于之前的值。它适用于如请求次数、错误次数等指标。
在查询栏中输入以下查询并执行。
go_gc_duration_seconds_count

PromQL 中的rate()函数会计算一段时间内指标值的增加速度,每秒增加多少。rate()只适用于 Counter。
rate(go_gc_duration_seconds_count[5m])

Gauge
Gauge 是一个可以增减的数字,用于诸如集群中 Pod 的数量、队列中的事件数量等指标。
go_memstats_heap_alloc_bytes

PromQL 中的max_over_time、min_over_time和avg_over_time函数适用于 Gauge 数据。
Histogram
与前两种相比,Histogram 是一种更复杂的指标类型。Histogram 可用于任何基于桶值进行计数的已计算值。开发人员可以配置桶边界。常见的示例是响应 API 请求所需的时间,这里称为延迟。
假设我们想要观察处理 API 请求所需的时间,Histogram 允许我们将其通过计数的形式存储在桶中,而不是为每个请求都存储处理时间。首先,我们定义几个消耗时间的桶,例如le 0.3、le 0.5、le 0.7、le 1 和 le 1.2,一旦测量到请求时间后,就会将其添加到边界高于被添加的测量值的对应桶中。
例如,端点“/ping”的请求 1 花费 0.25 秒。各个桶的计数值如下。
| 桶 | 计数 |
|---|---|
| 小于等于 0.3 | 1 |
| 小于等于 0.5 | 1 |
| 小于等于 0.7 | 1 |
| 小于等于 1 | 1 |
| 小于等于 1.2 | 1 |
| 小于等于 +Inf | 1 |
注意:+Inf 桶默认添加。
(由于 Histogram 是累计频率,因此所有大于值的桶计数都加上 1)
端点“/ping”的请求 2 花费 0.4 秒。各个桶的计数值如下。
| 桶 | 计数 |
|---|---|
| 小于等于 0.3 | 1 |
| 小于等于 0.5 | 2 |
| 小于等于 0.7 | 2 |
| 小于等于 1 | 2 |
| 小于等于 1.2 | 2 |
| 小于等于 +Inf | 2 |
因为 0.4 小于 0.5,所以所有这个边界内的桶都会增加计数。
我们可以通过 Prometheus UI 探索 Histogram,并应用一些函数。
prometheus_http_request_duration_seconds_bucket{handler="/graph"}

使用histogram_quantile()函数可以计算 Histogram 中的分位数。
histogram_quantile(0.9,prometheus_http_request_duration_seconds_bucket{handler="/graph"})
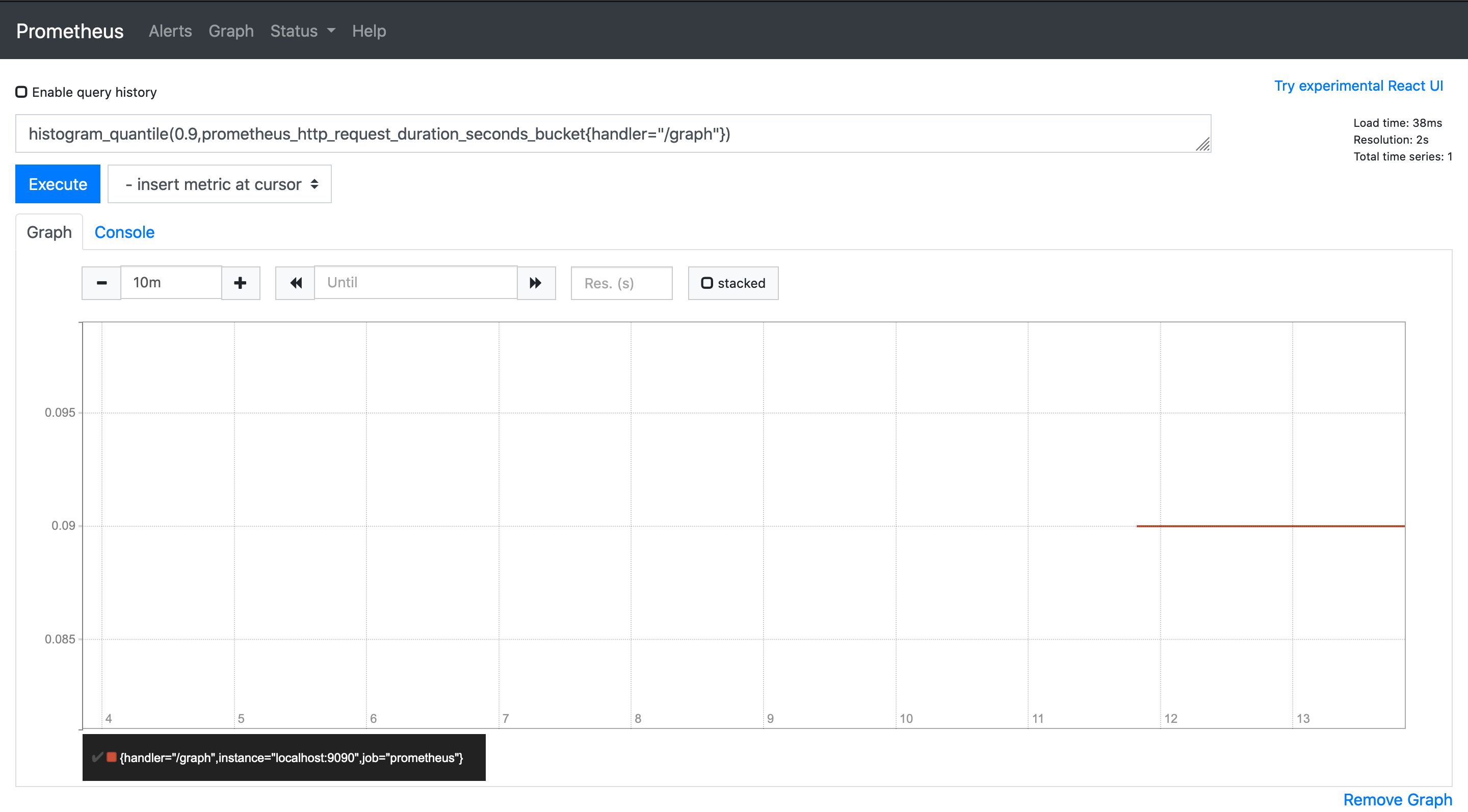
图表显示第90分位数为0.09。要查找过去 5 分钟的 Histogram 分位数,可以使用rate()和指定时间范围。
histogram_quantile(0.9, rate(prometheus_http_request_duration_seconds_bucket{handler="/graph"}[5m]))

Summary
Summary 也可以用于测量事件,能够作为 Histogram 的替代方案。相比起来,它更轻量但丢失的数据更多。在应用程序级别的计算过程中,Summary 无法从同一进程的不同实例聚合指标。当不知道指标的桶时,可以使用 Summary,但在一般情况下,还是推荐优先使用 Histogram 而非 Summary。
在此教程中,我们详细介绍了指标类型,并讨论了 PromQL 操作,如rate()、histogram_quantile()等。
该文档基于 Prometheus 官方文档翻译而成。