Opentelemetry 扩展:基于 eBPF 的全链路追踪技术
有幸参加了 Kubecon 2024 Hongkong 并与中山大学的杨婉琪博士一起分享了议题《OpenTelemetry Amplified: Full Observability with EBPF-Enabled Distributed Tracing》。
视频和 PDF 详见 链接。
背景
K8s 与 可观测
随着云原生的发展,我们的应用从开发到部署都发生了颠覆性的变化。从以前的单体应用到现在的微服务应用、从之前的物理机部署到如今的容器化。然而,基础设施的升级也对可观测提出了更高的要求。
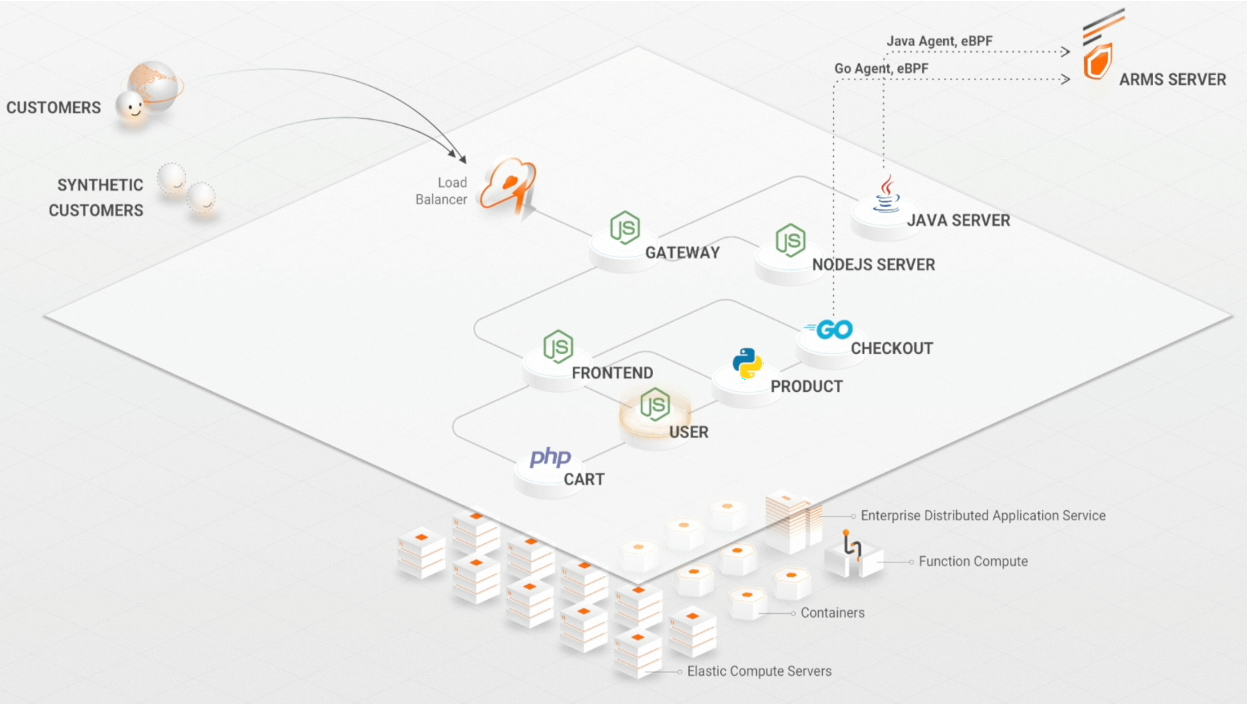
那么在 Kubernetes 中,我们需要如何建设可观测设施呢?我想我们需要从不同的角度来看待这个问题。
- 对于应用开发人员,我想知道我的应用性能表现如何?是否有过载现象?我想知道我的应用依赖了哪些中间件或者服务,以及这些服务之间的调用关系?对于多语言的微服务,我该如何快速的对这些应用进行观测?
- 对于网络运维人员,我想知道当应用表现出现异常时,是否网络通信被阻塞了?容器网络是否出现了故障?
- 对于网络安全人员,我想知道我的服务都操作了哪些资源?我想知道我的服务请求了哪些ip 地址?
OpenTelemetry 简介
OpenTelemetry 试图去解决云原生架构下的这些可观测问题。
OpenTelemetry 是一个可观测的框架,它提供了一系列的工具用来采集和处理遥测数据,包括 Metrics、Traces 和 Logs。
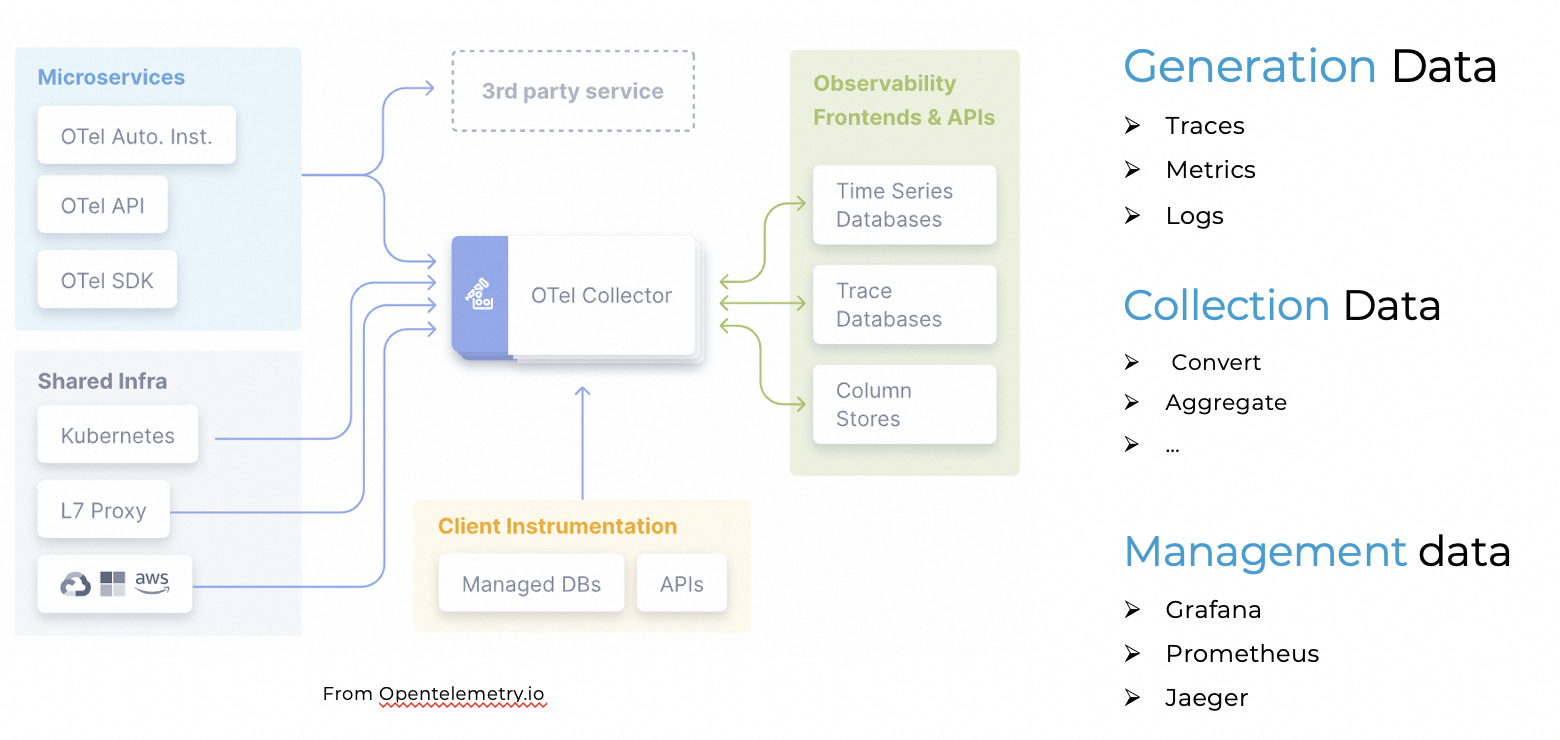
但是,OpenTelemetry 仍然存在很多的挑战。
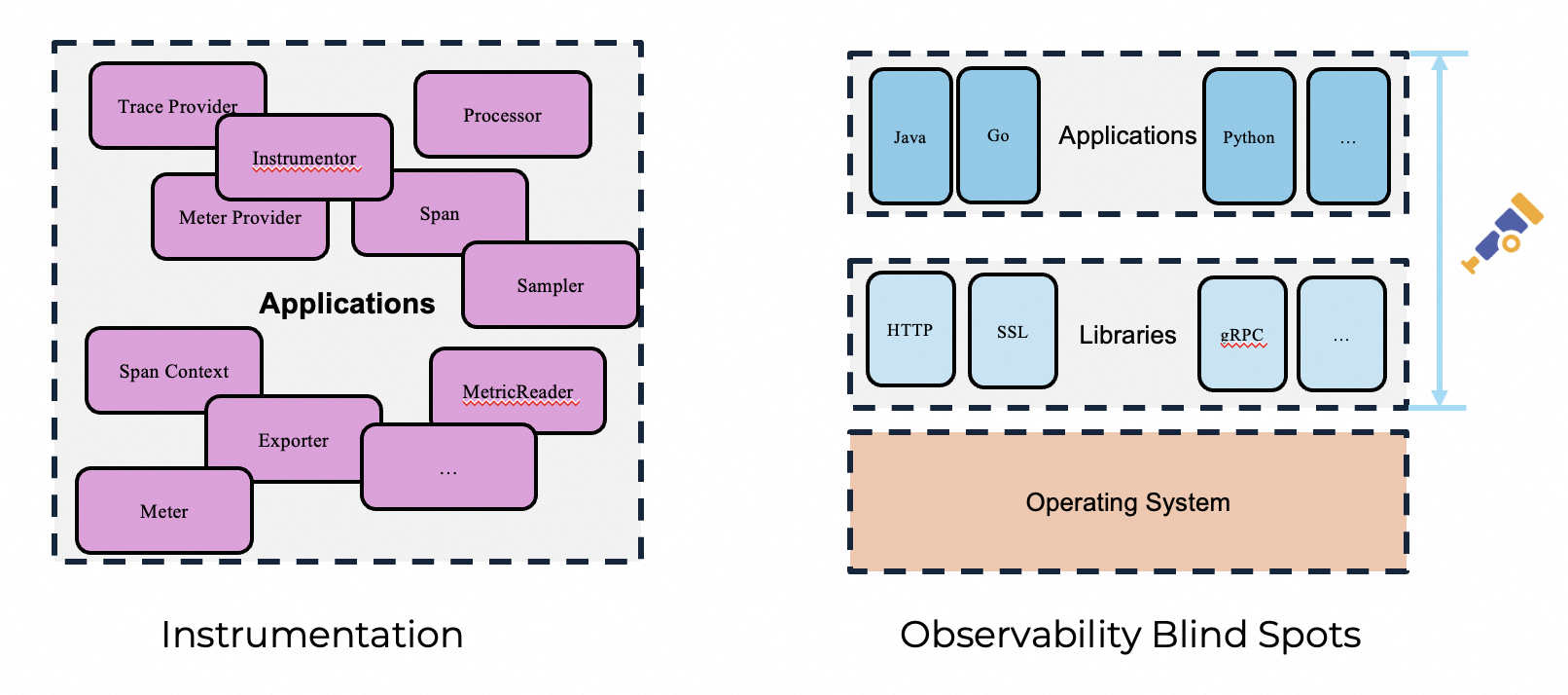
一方面,它有较高的 overhead。如果你使用过 OpenTelemetry ,并且你的开发语言不支持zero-instrument,那么你一定被很多名词困扰过,比如 TraceProvier、SpanContext、baggage、exporter 等等。它们都会与你的应用一起运行,所以可能会导致性能的下降。
另一个挑战是 OpenTelemetry 对于操作系统内核的观测能力较弱,它更多是关注了应用层的观测。那么假如我们的网络协议栈出现了异常,OpenTelemetry 通常无法回答异常的原因。
因此,我们试着使用一种新的技术来解决 Kubernetes 中的可观测问题,它就是 eBPF。
eBPF 简介
eBPF(extened Berkeley Packet Filter)是一种内核技术,它允许开发人员在不修改内核代码的情况下运行特定的功能。
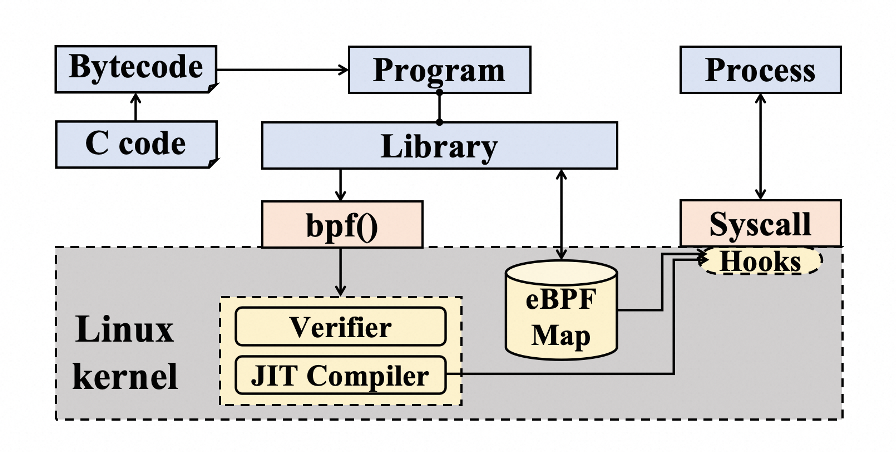
eBPF允许用户在Linux内核中运行沙箱程序,且无需更改内核源代码。开发人员编写好的eBPF程序会被加载到内核中,并挂载到特定的钩子点上,比如网络事件或文件系统操作。eBPF程序定义了不同的程序类型,分别对应不同的钩子点,比如kprobe和uprobe程序分别会挂载到内核函数和用户函数的入口位置。当被挂载的函数被调用时,对应的eBPF程序也会被触发执行。从C代码编译成字节码后,eBPF程序需要通过eBPF验证器验证以确保安全性,防止内存越界访问等安全问题。
eBPF Map是eBPF定义的键值存储的数据结构,用于在eBPF程序和用户空间之间存储和共享数据,并支持持久的数据存储。
基于eBPF,我们可以将请求追踪的工作下沉到内核空间,将其与用户程序解耦。这种方法无需修改或插桩用户程序,从而减少了在用户空间中请求追踪的开销。
虽然eBPF和Linux内核模块(LKM)都对内核功能进行扩展,但它们在设计和用法上有所不同。得益于eBPF的验证器,eBPF允许在内核中安全、低开销地执行用户自定义的代码,而无需修改内核源代码。相比之下,LKM提供了更大的灵活性,但也带来了更高的开销和风险,比如潜在的系统崩溃。

因此,由于eBPF的安全性和轻量级,我们选择它来实现我们的在内核空间的端到端请求追踪。
端到端的 request tracing
使用 eBPF 实现分布式链路追踪,社区也在不断的探索。
目前社区中比较有代表性的项目是 opentelemetry-go-instrumentation,这是一个针对 Golang 语言的完全基于 eBPF 实现的探针。它不需要 Golang 代码集成 Otel SDK,也不需要应用进行重启,便可以完成应用的注入。
但是,该项目存在很多问题,详情可以参考文章,这里只简单列举几个比较严峻的挑战:
- 埋点全部使用 uprobe 实现,仅适用于 Golang 应用程序;
- 无法解析某些 Golang 数据结构。比如 map,在解析消息时仅支持 HTTP 头中有限数量的键值对的解析,故不支持拥有更多数目键值对的消息的解析和追踪。
因此,我们希望提供一个自动化的请求跟踪系统,支持多种高级语言框架,并且不受HTTP头键值对数量的限制。
架构
下图描述了我们基于eBPF的分布式跟踪框架的工作流程,其中黑线表示消息传输方向,红线表示我们收集span数据的流向。

我们的系统主要运行 2 个模块:Trace 的生成和 Trace 的采集。Trace 生成模块包括三个子模块:trace 上下文的生成、服务间的 Trace Context 传递以及服务间的 Trace Context 传递。Trace 采集模块负责收集系统生成的 Trace 和 Span,以便后续的可视化。
原理
上下文生成
我们以 OpenTelemetry 的标准生成 TraceContext。
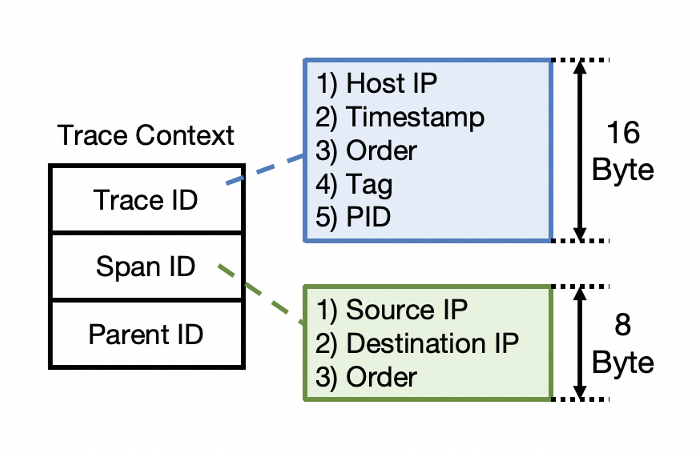
一个 Trace Context 由 TraceID、SpanID 和 父 SpanID 组成,唯一标识一个 Span。TraceID 是一个16字节的值,包括主机 IP 地址、请求入口时间戳、序列号、用于调试的标记和进程 ID。SpanID 是一个8字节的值,包括源 IP 地址和目的 IP 地址以及序列号。
服务间上下文的传播
为端到端请求中的每个操作生成唯一的 Trace Context 后,我们的系统需要在服务间传递这些上下文。通过分析 HTTP 请求格式,我们使用 W3C 标准,在 HTTP 头部信息中携带 Trace Context,以实现上下文在网络中的传递。

如图所示,当服务接收到带有 Trace Context 的请求时,挂载到内核函数 sock_recvmsg 上的 eBPF 程序会拦截该请求并从中提取上下文。此过程不需要从请求中删除上下文。当服务需要向上游发送请求时,我们sk_msg的 eBPF 程序会将 Trace Context 作为自定义的键值对注入到请求头部。此过程会增加发送消息的长度。
服务内的上下文传播
端到端的请求追踪的关键是准确地识别请求的因果关系。为了实现这一点,我们的系统必须在服务内部有效地将trace上下文从父请求传递到子请求。
由于每个应用程序在用户进程上的调度是始终保持一致的,因此我们重点关注如何在内核空间中捕获用户线程的创建,以此来了解线程的执行及线程间的父子关系。
应用程序主要以两种方式处理请求:
- 单线程应用在单个线程中响应请求、且发送上游请求和等待上游响应在同一个线程中完成;
- 多线程应用往往由多个线程共同协作来响应请求。在简单的场景中,应用程序会创建线程并调度空闲线程来请求上游服务;
- 多线程应用程序还会使用线程池或协程来响应请求。应用会创建任务或协程来请求上游服务或执行其他操作,如读取文件。这些任务会被放置在任务队列中,等待线程池中的空闲线程来执行。如果一个线程完成了调度到其上的任务,它会被重新放入线程池,并记录为空闲状态,直到它再次被分配一个新任务。
基于上述三个应用执行模型,下面讨论我们的系统如何在服务内部透传trace上下文。
单线程
对于单线程应用程序,我们为每个线程使用唯一的线程ID来传递trace上下文。当接收到来自下游的请求时,服务会使用其线程ID作为键来存储trace上下文。当服务向上游服务发送请求时,该上下文会被相同的线程ID检索得到,而后作为父trace上下文。然后子trace上下文会被生成,并被注入到对上游服务的请求中。

多线程
在简单的多线程应用程序中,当一个线程创建一个子线程来请求上游服务时,我们的系统会监控线程创建的过程以捕获线程的父子关系。当子线程向上游服务发送消息时,我们的系统会识别对应的父线程,然后以此作为键来检索父trace上下文和生成相应的子trace上下文。
在更复杂的场景中,多线程应用程序使用线程池或协程机制,通过最小化创建和销毁线程的开销来提高性能。
这幅图展示了我们的系统如何在线程池应用程序中传递trace上下文。

由于多个任务可以分别调度在同一个线程上运行,因此使用任务ID传递trace上下文会比使用线程ID效果更优。通过挂载eBPF程序到任务创建过程,我们的系统可以获得任务的父子关系。我们的系统同时还监控线程上的任务调度和执行情况,以获取任务的调度信息。
当线程请求上游服务时,我们的系统会基于正在运行的任务ID或父任务ID检索得到父trace上下文,然后生成子上下文并将其注入到该请求中。
表格中列出了我们的系统用于采集有用信息的一些重要的eBPF程序及其钩子点。

Demo
为测试我们系统的功能和性能,我们使用了 Istio 提供的 Bookinfo 应用。Demo 应用的架构如下图所示:

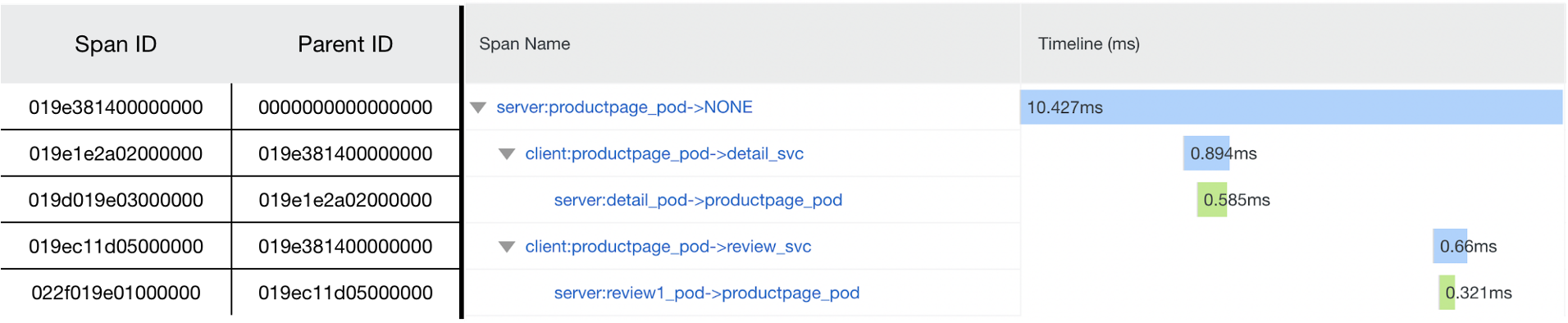
下面这幅图展示了我们系统为 Bookinfo 应用程序生成的一个 Trace 。在处理用户请求时,productpage 服务会调用 detail 和 review 服务,从而产生 5 个 span。这结果表明我们的系统能够准确地捕获请求的因果关系,并为端到端请求生成对应的 Trace。
为了评估追踪 Bookinfo 应用程序请求的系统开销,我们构建了一个拥有 5 台物理机器的 Kubernetes 集群。这些机器在基于 centos -8 的操作系统上运行,Linux 内核版本为 5.10.134,拥有 16 GB 的内存。
实验过程中,我们生成 600 个并发用户的工作负载。每次实验运行三分钟,重复三次。平均实验结果如表格所示。
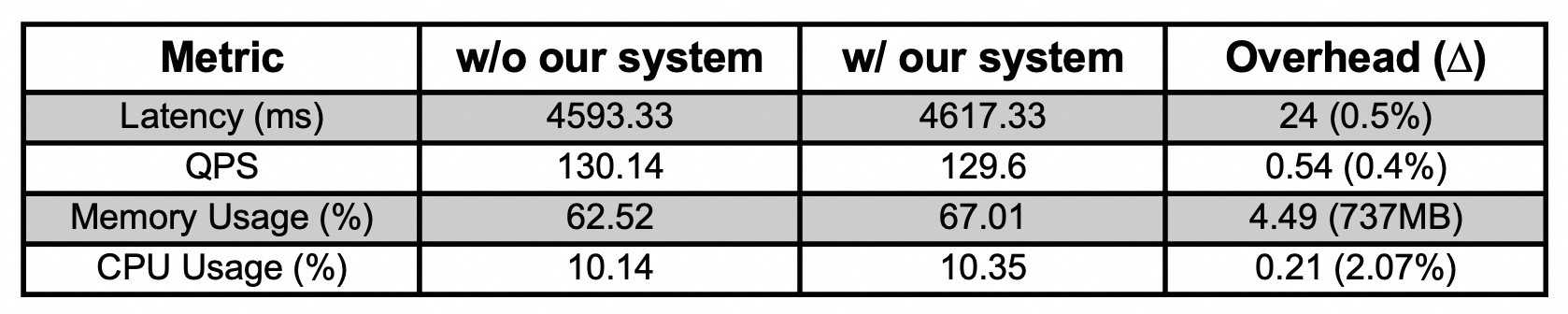
在服务性能方面,我们的系统相比正常情况增加了约 0.5% 的请求延迟,并降低了约 0.4% 的服务QPS。这些额外的延迟来源于 eBPF 程序在 Linux 内核中拦截和解析消息的时间开销。
在资源消耗方面,我们的系统比正常情况增加了大约 4.5% 的 CPU 使用率,相对增加 2%。
注:目前数据是实验环境,没有做过多的优化,所以当前实测下来内存开销较大。后续我们在落地过程中会进行优化,预计内存会在 1w TPS、 300M 左右的水位。
内核事件的关联
基于以上的内容,我们基于 eBPF 实现了统一的 request tracing。这使得我们无需理解 OpenTelemetry 中的一些复杂的名词,通过 zero-instrumentation 便可以观测应用的性能以及请求的链路。而且 eBPF 拥有接近机器码的执行效率,这种方式为应用带来的额外开销也比较低。
但是我们仍然无法回答一些来自内核中的异常。如果我们的某个服务出现了异常,并且我无法从代码中找到 bug,这时候我会希望了解我的应用在内核中到底经历了什么。它是否遇到了一些内核中的错误?这些错误来自于哪些线程?以及是否是网络协议栈出现了阻塞?
为了回答这些未知的问题,我们尝试采集一些重要的内核方法的执行信息并集成到应用层的 Trace 中?
基于这个想法,我们需要做三件事情:
- 我们需要采集到kernel function 的观测数据
- 我们需要在内核中,完成 kernel functions 之间的 Context Propagation
- 我们需要将内核与应用层的观测数据进行融合,这样我们就可以从 request-level 中获得 kernel-level 的 insights
内核事件采集
在内核空间,我们需要采集 kernel functions 的一些运行时信息,包括时间戳、执行时间、参数和返回值。这个流程与用户空间中的数据采集是类似的。

eBPF 支持将 custom code 挂载到 kprobe 和 kretprobe 中,这两个 hook 位置分别对应了 kernel function 的进入和退出。具体的流程我们可以参考上图,在 进入kernel function 时,我们记录 timestamp 以及 arguments,在退出 kernel function 时,我们将记录返回值以及 duration。
内核中的上下文传播
接下来,我们需要完成 kernel functions 之间的 Context Propagation。
在内核中,对于 Context Propagation,我们同样需要考虑两种线程模型,分别是同步模型和异步模型。
同步线程模型
对于同步模型,我们可以细分为两种调用方式。也就是串行调用和父子调用。
我们假设这里有一个线程,而且线程的 Context 中记录着一个名为 parent span 的 span。
针对串行调用,也就是说在 Kernel Function 1 和 Kernel Function 2 是顺序调用的。让我们来看图1中描述的处理过程,当cpu进入 kernel function 1 时,我们将基于当前线程的 Context 创建 Span1,并将 Span1 记录在当前 Context 中。此时,线程中的 Span 则 从 parent span 变成了 span1。 当 cpu 退出 kernel function 1 时会将 span1 从 Context 中移除。此时线程的 Context 记录的span 再次变成了 parent span。那么在执行 kernel function2时也是一样的处理流程。在进入 kernel function2 时记录 span2,退出时恢复成 parent span。因此,我们可以看到串行调用的链路中,kernel func 1 和 kernel func2 是同级的关系,都属于 parent span。
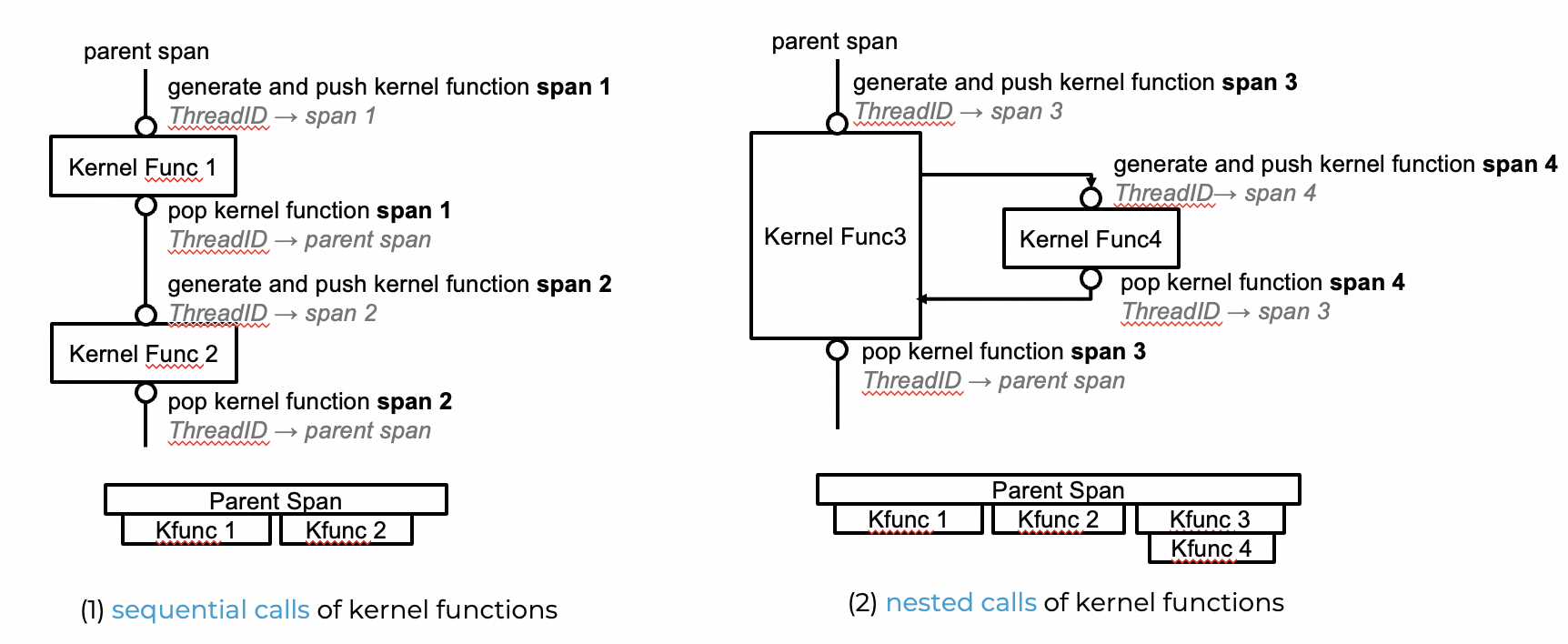
父子调用意味着在调用 kernel function 3 时,在它执行的过程中调用了 kernel function 4。在这种场景下,cpu 在进入kernel function 3时,同样会基于线程的 Context 创建 Span 3。不同于串行调用,此时cpu并不会先将 Context 中的 span 恢复成 parent span,而是会先执行 kernel function 4 并基于 Span3 创建 Span4。所以,我们可以看到 Trace 中, kernel func 3 和 kernel func 4 不再同级,kernel func 4 属于 kernel func 3。
异步线程模型
接下来是异步的线程模型。在 linux kernel 中存在着很多的内核线程,而且这些线程不属于业务应用。
直接将内核线程和用户线程进行关联是非常困难的,但是我们可以通过 linux 不同子系统的特征来寻找解决方案。
我们以网络协议栈为例。

在 network 子系统中,skb 是一个非常特殊的结构,它用来承载网络通信的数据包。因此,我们可以通过 skb 来携带链路的 Context。我们假设 kernel func5 和 kernel func5 是不同内核线程用来处理数据包的函数。那么当cpu执行kernel func5时,我们首先需要基于当前线程的Context创建 Span5,但注意,此时我们不能仅通过 线程id 来记录 Context,还需要将 Context 与 Skb 绑定起来。因此我们还将记录 当前 SKB 中的 Span 为 Span5。这样,当其他线程执行 kernel func6 时。通过查询当前 Skb 对应的 Context,则可以感知到当前的 Span 为 Span5,接着则根据Span5创建 Span6。从而完成了异步场景中的Context Propagation。
关联
由于我们已经完成了内核中的链路观测,接下来,我们需要对内核与应用层的观测数据进行融合。
我们知道,用户空间和内核空间的交互通过 syscall 来完成的,因此我们可以选择将 syscall 作为两者的纽带。

根据上图,我们首先在各个Linux 子系统中完成数据的采集和 context propagation。我们仍然以 network 子系统为例,我们在做上下文透传时,需要同时更新 skb 的 SpanContext 和 thread 的 SpanContext。当进程通过 syscall 获取内核的数据结构时,需要先从 thread Context 中获取当前的 SpanContext,如果能获取到,我们则使用当前线程的 Context。如果当前线程没有 spanContext,比如我们通过 sys_read 获取网络字节流,我们则需要解析参数,从 buffer 中提取 Context。后续的处理就是本文之前介绍的 request tracing 流程了。
Demo
最后,让我们来看一下链路的最终效果。
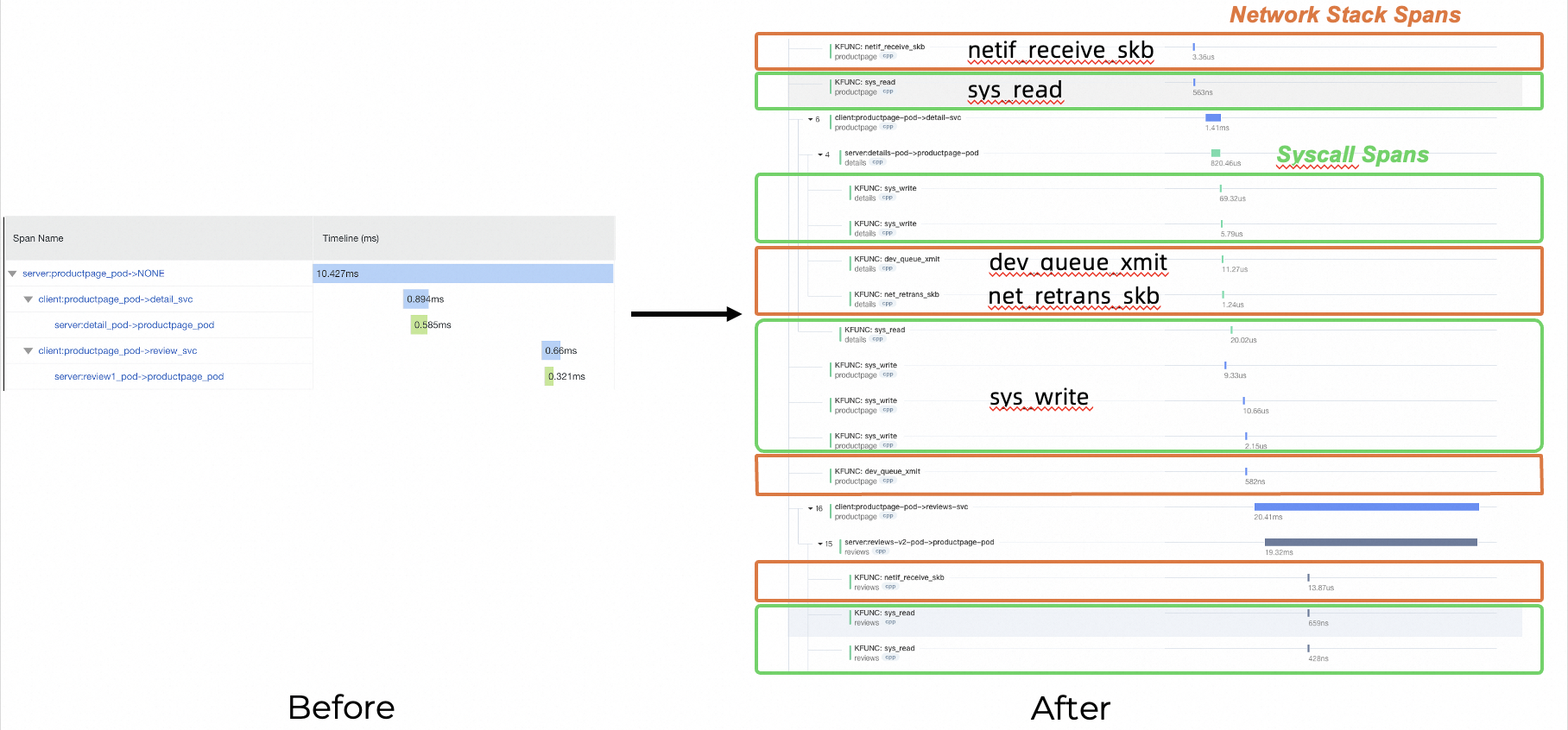
对比左侧的 request tracing,我们额外观测到了许多内核的行为。我们可以看到网络协议栈中收发数据报文的流程,我们也可以看到通过系统调用读写文件的操作。
方案限制
我们基于 eBPF 实现了无侵入(zero- instrumentation)的分布式链路追踪能力,观测的范围覆盖了用户空间和内核空间。但是,由于 eBPF 存在一些限制,因此我们的系统也存在一些局限性。
- 我们需要用到一些特定的 bpf helper functions,因此,我们需要 Linux 内核版本在4.20及以上;
- 我们仅实现了 W3C 协议的透传,其他协议暂未支持;
- 由于我们需要在内核空间通过 eBPF 来解析网络字节流,因此我们无法处理加密协议,比如 HTTPS
- 对于流式通信协议,由于它的每个frame 都是有状态的,在内核中解析非常困难,因此我们目前也无法支持。
未来规划
面相未来,我们规划了四个目标。
- 支持更多种类的应用层协议,比如我们常用的 MySQL、Kafka;
- 支持网卡监控,用来提供更深层次的网络监控能力,可以追踪数据包的在网络中的旅程;
- 将完整的能力集成到阿里云应用监控eBPF版中,提供开箱即用的能力;
- 将代码进行开源。