opentelemetry-go-instrumentation 原理
背景
opentelemetry-go-instrument 是 ot 官方的 golang 无侵入观测方案。它基于 eBPF 和 uprobes 实现了链路追踪的能力。
项目地址: opentelemetry-go-instrumentation
eBPF 简介
eBPF(Extended Berkeley Packet Filter)是一种强大的内核技术,能够在 Linux 内核中动态地运行小段安全的程序。这些程序可以用于网络监控、性能分析、安全性增强等多个领域,极大地扩展了 Linux 内核的功能与灵活性。
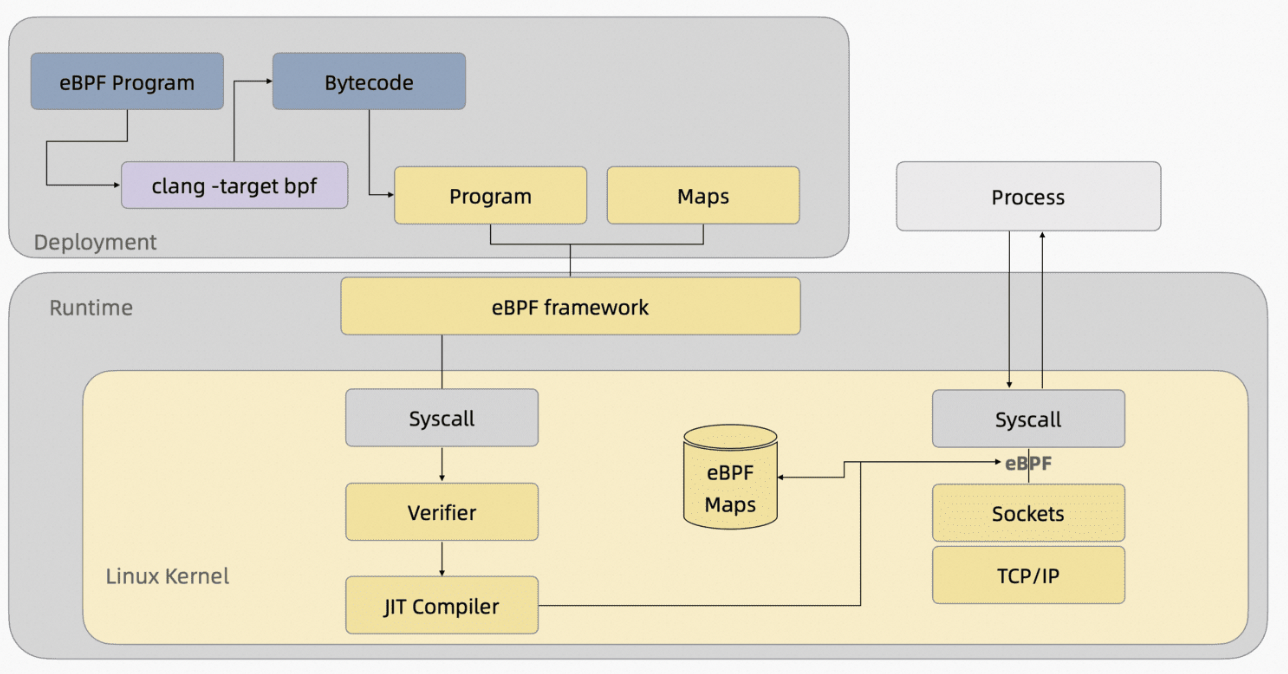
工作原理
eBPF 的工作原理是允许用户空间应用程序将小片段的代码(称为 eBPF 程序)加载到内核中,并在指定的事件触发时执行。eBPF 程序可以插入到多个钩子(hook)位置,如网络数据包处理、系统调用、trace points 等。当事件发生时,相应的 eBPF 程序被调用,从而实现对系统行为的监控、修改或跟踪。
特点
-
动态性:开发者可以在运行时加载和修改 eBPF 程序,而无需重启内核或重新编译内核模块。
-
安全性:eBPF 程序在被加载到内核之前,会通过一个称为“验证器”(verifier)的安全审核过程,此过程确保程序在执行时不会造成系统崩溃或安全漏洞。
-
高性能:eBPF 程序在内核中运行,避免了用户空间与内核之间的上下文切换,因此能实现高效的性能监控与处理。
-
丰富的生态系统:众多高层应用(如 Cilium、bpftrace、Falco 等)已经建立在 eBPF 之上,提供了强大的功能和易用的接口。
应用场景
- 网络监控:利用 eBPF,网络管理员可以实时分析网络流量,监测性能瓶颈,并实现精准的流量控制。
- 性能分析:开发人员可以使用 eBPF 在运行时收集性能数据,以帮助调优应用程序和协议栈的性能。
- 安全性增强:eBPF 可用于实现行为监控、入侵检测等安全防护措施,针对可疑行为生成警报或自动响应。
eBPF 观测 Golang 的挑战
内核版本限制
_eBPF的完整能力通常需要内核版本在 __**4.14 __以上,如果使用BTF来解决CO-RE问题,则需要至少 __5.x **_的内核才可以有较好的支持。
内核版本较低会导致节点上的eBPF埋点失效,从而导致Trace断链的问题。
eBPF限制
eBPF是运行在Linux内核中的虚拟机,它拥有自己独立的指令集,不可避免的会带来很多的编程限制。
隔离性
eBPF 程序运行在内核空间,而用户空间的函数运行在用户空间。eBPF 不能直接访问用户空间的内存或调用用户空间的代码。
这就意味着,如果我们想判断两个字符数组buf1和buf2是否相等,在用户进程中,我们可以通过很简单的方法就可以完成:
if (!strncmp(buf1,buf2,4)) return true;但是,在eBPF代码中,我们不能直接调用用户空间提供的方法,因此,我们只能逐位进行比较。
if (buf1[0] == buf2[0] && buf1[1] == buf2[1] && buf1[2] == buf2[2] && buf1[3] == buf2[3]) return true;指令数
出于安全和性能考虑,eBPF代码是有指令数的限制的,在5.x内核版本之前,通常为4096;在比较新的内核中,这个限制扩展到了100w条。
该限制条件在 eBPF 代码中存在循环语句时会更加严格。
如果我们的指令数过多,则需要通过tailCall的方式进行级联。
栈空间
eBPF 程序的栈大小限制为512字节
eBPF 的栈很小,这就要求我们在编写 eBPF 程序时必须非常高效地使用栈空间,尽量避免大量的栈分配。例如,大型的局部变量或大数组应该尽可能地避免在栈上分配。此外,深层次的函数调用栈也可能耗尽这个有限的栈空间,从而导致程序无法加载或运行。
修改用户空间内存
eBPF 提供了 bpf_probe_write_user 来修改用户空间的内存
函数原型:
int bpf_probe_write_user(void *dst, const void *src, int size)该函数会将 size 字节从 eBPF 程序中的内存(src)复制到用户空间的指定位置(dst)。使用这个函数有很多限制,包括对可调用这个函数的 eBPF 程序类型的限制,以及严格的安全性验证。
此外,由于修改用户空间的内存可能会导致未定义行为,这通常被认为是危险的,应当谨慎使用。可能会有下面的风险:
- 引起用户空间程序崩溃或数据损坏
- 破坏进程间的内存隔离,带来潜在的安全风险
- 触发用户空间程序意外行为,可能引起安全漏洞
除了以上的安全隐患之外,该方法还有一个致命的缺陷,即只能拷贝min(len(dst), size)的数据到dst中。
举个例子,比如我们需要hook一个用户态的testHack方法,替换该方法的入参。用户态的Golang代码如下:
package main
import ( "fmt" "os" "time")
//go:noinlinefunc testHack(s string) { fmt.Println(s)}
func main() { for { testHack(os.Args[1]) time.Sleep(time.Second) }}eBPF代码如下:
int probe_main_test_hack(struct pt_regs *ctx) { char text[] = "qianlu: hacked msg!!!!"; u64 addr = 0; u64* sp = (u64*)ctx->sp; bpf_probe_read(&addr, sizeof(addr), sp + 1); bpf_probe_write_user((u64*)addr, text, sizeof(text)); return 0;}先将用户态Golang代码启动几秒后,通过uprobe将eBPF代码挂载到testHack方法中:
$ ./main 'qianlu: origin msg'qianlu: origin msgqianlu: origin msgqianlu: origin msgqianlu: origin msgqianlu: hacked msgqianlu: hacked msgqianlu: hacked msgqianlu: hacked msgqianlu: hacked msg...可以看到,我们通过uprobe成功修改了用户空间的内存。但是,我们替换后的字符串并没有完全输出,因为dst只开辟了len(s)的空间。
uprobe性能问题
uprobe(用户空间探针)是 Linux 内核的一个特性,允许开发者附加 eBPF 程序或 kprobes 到用户空间应用程序的函数和代码地址上。这使得开发者能够观察和分析用户空间程序的行为,例如监控函数的调用次数、参数值,或是收集性能数据。
使用 uprobes 会对被监控的程序产生一定的性能开销。具体的性能影响取决于多个因素:
- 探针的数量:如果对于某一个用户态方法上挂载了大量的 uprobe,可能会导致显著的性能影响,因为每个探针触发时都会执行额外的代码。
- 探针的位置:如果 uprobes 附加到频繁调用的函数上,那么性能影响会更大,因为这些探针会被触发得更频繁。
- 执行的操作:eBPF 程序的复杂程度也会影响性能。一些简单的操作,如增加计数器,可能对性能影响很小,而更复杂的数据收集和处理会带来更大的性能开销。比如通过 BPF Map 或者 perfBuffer 发送数据。
- 上下文切换:uprobes 触发时,如果挂载的是 eBPF 程序,则会有从用户空间到内核空间的上下文切换,直接影响到CPU的使用率。
uretprobe限制
uretprobes 是 Linux 内核中的一个特性,类似于 uprobes,但它们是附加在函数返回时触发的。当你对一个特定的用户空间函数设置 uretprobe 时,它会在目标函数即将返回时触发,允许你检查函数的返回值或执行其他在函数退出时需要做的操作。
uretprobes 的工作原理是在目标函数的入口附加一个 uprobes,当函数被调用时,uprobes 修改返回地址,指向一个内核控制的 trampoline 地址。当函数执行完毕并准备返回时,它会跳转到这个 trampoline,这个 trampoline 随后会触发 uretprobe 关联的处理程序。处理完成后,控制权返回到原始的调用者。
结合uprobes和uretprobes,我们就可以统计某个用户态方法的入参、返回值以及调用时间等信息。
然而,由于原因是 Golang 的运行时(runtime)使用了不同的调用约定和栈管理方式,与 C 语言等语言不同,因此会影响 uretprobes 的正常工作。具体来说,有以下的问题:
- 调用约定:Go 语言使用自己的调用约定,而非传统的 C 语言调用约定。由于 uretprobes 设计时假设了特定的调用约定(比如 C 语言的调用约定),因此对 Go 语言的函数可能无法正确工作。
- 栈管理:Go 的运行时使用了分段的栈,可以_动态地增长和收缩_,这与 C 语言程序的连续固定大小栈不同。因此,探针可能无法总是准确地找到返回地址。
- 内联和优化:Go 编译器可能会对代码进行内联或其他优化,这可能使得函数没有明确的返回点,或者返回点在运行时不固定,给 uretprobes 带来挑战。
- 垃圾回收:Go 的垃圾回收机制可能会移动对象,包括栈帧,这使得在栈上设置断点变得更加困难。
Golang栈帧问题
栈帧是用来保存函数调用过程中的各种信息,比如参数,返回地址,本地变量等。
在对 Golang 进程进行观测时,我们一定会需要具备捕获每个方法运行时的入参、返回值等信息的能力。
而 eBPF 运行在内核态,只能获取到寄存器的信息,而无法直接确定入参、返回值的具体对应关系。这就需要我们对 Golang 的栈帧进行解析。
Golang 栈帧具有以下的特性:
- 在golang中,栈帧是一次性分配完成
- 不论是参数还是返回值,都是从右到左依次入栈
- Go1.17之前,返回值函数调用前需要在栈上预留空间
- Go中传参永远是值拷贝
- Go1.17以前,所有的参数和返回值都放在栈上

- Go1.17及以后,前9个参数和返回值使用寄存器,之后的参数和返回值使用栈,(寄存器的使用顺序如图所示)

- 对于方法而言,方法对应的结构体会放在第一个参数的位置(如果结构体中的内容在方法体里面并没有使用到的话,也可能被编译优化掉),传参规则和其他参数相同。
埋点稳定性问题
通过栈帧确定了各个参数的位置后,我们还需要解决埋点稳定性的问题,具体来说主要包含两类:
- 框架版本不同,导致的方法签名变动;
- 参数中可能存在复合类型,比如结构体,在解析结构体中某个成员时,其偏移量会受到编译器版本、系统架构等影响。
方法签名
Golang 中很多框架中的方法签名都发生过变化。我们以 gRPC 为例:
service MyService { rpc MyMethod(MyRequest) returns (MyResponse);在以前的 gRPC 版本中,是不都提供 context.Context 作为参数的。后续版本的变化允许在所有的 RPC 方法中使用 context.Context。
变化前
func (s *MyService) MyMethod(req *MyRequest) (*MyResponse, error)变化后
func (s *MyService) MyMethod(ctx context.Context, req *MyRequest) (*MyResponse, error)因此,如果我们通过 uprobe 挂载 MyMethod 方法,由于不同版本中,方法签名会发生变化,因此我们只能在运行时分析每个方法的实际签名。
offset
需要确定offset。举个例子,比如下面的结构体People:
type People struct { Name string // size: 4 or 8 (depends on architecture) Age int // size: 4 (32-bit) or 8 (64-bit) Gender int // size: 4 (32-bit) or 8 (64-bit)}内存对齐规则:
- 在 32 位系统中,int 的对齐要求是 4 字节。
- 在 64 位系统中,int 的对齐要求是 8 字节。
在32位系统中:
- Name 字段:
- 偏移量: 0 字节。
- Age 字段:
- 在 Name 后,Age 紧接着存放,因为 Name 在 32 位中占用了 4 字节。
- 偏移量: 0 + 4 = 4 字节。
- Gender 字段:
- Age 字段后紧接着而存放,Age 占用 4 字节。
- 偏移量: 4 + 4 = 8 字节。
在64位系统中:
- Name 字段:
- 偏移量: 0 字节。
- Age 字段:
- 在 64 位中,Name 占用 8 字节。因此,在 Age 字段紧接着 Name 字段之后。
- 偏移量: 0 + 8 = 8 字节。
- Gender 字段:
- Age 占用 8 字节,紧接着是 Gender。
- 偏移量: 8 + 8 = 16 字节。
开发复杂度问题
基于上文中列举的一些问题,我们在通过 eBPF 对 Golang 程序进行探测时,需要感知:
- Golang 栈帧分布
- 组件框架的版本
- 核心数据结构的内存排列
- …
此外,我们还需要在特定的 eBPF 指令集中完成数据采集,其开发复杂度远高于开发用户态 SDK。
opentelemetry-go-instrument 原理
部署形态
Daemonset模式部署
核心原理
TraceID注入
注入TraceID主要需要以下几步:
- 根据W3C标准,获取上游传递的TraceID,如果没有则重新生成;
- 根据W3C标准,找到插入TraceID的位置;
- 根据框架实现的特性,分析是否需要分配内存;
- 通过bpf_probe_write_user注入TraceID。
其中,注入 TraceID 主要依赖 bpf helper function bpf_probe_write_user 来修改用户空间的内存。上文中提到该 helper function 存在一些问题,比如无法开辟新的内存。otel 克服了这个问题,它通过 BPF Map 实现了类 allocator 能力,将 golang map value 中的指针,通过 BPF Map 中的堆上内存进行了替换。
解决埋点稳定性
决议符号的offset,有两种方式:
- 基于DIE信息;
- 通过拉取对应版本的源码,决议出每个Field相较于Struct的偏移量。
目前opentelemetry-go-instrumentation使用的是2的方案。
解决uretprobe
根据elf读取func返回语句的地址,然后以uprobe的方式挂载到该地址,模拟uretprobe的行为。
支持框架
| 框架 | role | 限制 |
|---|---|---|
| database/sql | client | 无 |
| gin | server | 无 |
| net/http | client | header size < 8 |
| server | 无 | |
| grpc | client | 无 |
| server | 无 |
技术难题
虽然 otel 解决了很多 eBPF uprobe 的问题,但是仍存在很多的技术难题,导致目前生态不够丰富且无法大规模使用。
- 性能:uprobe 的性能始终是无法回避的难题,额外增加的往返内核态开销在高 QPS 场景会耗尽 cpu。
- 复杂数据结构的解析:对于 golang 这种高级语言,有很多数据结构强依赖用户空间的信息,比如 map、chan 等,eBPF 所获取到的寄存器信息太过于有限了,只能解决小部分的场景,这也是很多中间件、插件无法支持的原因。
其他方案
SDK方式
集成 SDK 可以细分为以下 2 类:
- 手动引入SDK,并且通过go replace替换包,目前很多云厂商和社区都提供这种机制;
- 通过分析 go 代码中的包依赖关系,自动化执行 go replace,比如 opentelemetry-instrgen
编译期注入
编译期注入依赖于Golang的go tools能力,以下是目前比较优秀的项目:
对比
| 侵入性 | 稳定性 | 插件开发复杂度 | Trace能力 | |
|---|---|---|---|---|
| eBPF x uprobe | 低 | 低 | 高 | 弱 |
| sdk | 高 | 高 | 低 | 强 |
| go tools | 中 | 高 | 低 | 强 |
结论
整体来看,eBPF 方式是侵入性最低的方案,但是却存在种种限制,而且很多还是技术鸿沟,无法跨越。
相比之下,可能进程内的探针才是云上最朴实的选择。尽管存在一定的侵入性,但是综合考虑扩展性、开发复杂度、Trace能力等多方面的因素,这仍然是能够持续发展的最佳方案。