插件系统
背景
作为日志服务的采集 Agent,iLogtail 目前已运行于 100W+ 机器上,为万级别的应用提供服务,为了能够更好地实现与开源生态的融合并满足用户不断丰富的接入需求,我们为 iLogtail 引入了插件系统,目前,我们已通过插件系统支持了若干数据源,包括 HTTP、MySQL Query、MySQL Binlog 等。
本文将对 iLogtail 插件系统进行简要介绍,包括插件系统的实现原理、插件系统的组成及设计。
实现原理
本节我们以如下流程图来说明 iLogtail 插件系统的实现原理。

为了支持插件系统,我们引入了 libPluginAdaptor 和 libPluginBase(以下简称 adaptor 和 base)这两个动态库,它们与 iLogtail 之间的关系如下:
-
iLogtail 动态依赖于这两个动态库(即 binary 中不依赖),在初始化时,iLogtail 会尝试使用动态库接口(如 dlopen)动态加载它们,获取所需的符号。这种设计的好处在于:即使动态加载失败,也仅仅是插件功能不可用,不影响 iLogtail 本身已有的功能。
-
Adaptor 充当一个中间层,iLogtail 和 base 均依赖它,iLogtail 首先注册回调,adpator 将这些回调记录下来,以接口的形式暴露给 base 使用。这间接构成了 base 调用 iLogtail 方法,从而 base 不会依赖 iLogtail。这些回调中的一个关键方法为 SendPb,base 可以通过它将数据添加到 iLogtail 的发送队列,进而递交给 LogHub。
-
Base 是插件系统的主体,它包含插件系统所必须的采集、处理、聚合以及输出(向 iLogtail 递交可以视为其中一种)等功能。因此,对插件系统的扩展实质上是对 base 的扩展。 回到流程图,我们来简要说明下其中的各个步骤:
-
iLogtail 初始化阶段,动态加载 adaptor,并通过得到的符号注册回调。
-
iLogtail 初始化阶段,动态加载 base,获取符号,包括本流程中所用到的 LoadConfig 符号。Base 在 binary 上依赖了 adaptor,所以这一步它会加载 adaptor。
-
iLogtail 从 LogHub 处获取用户的配置(插件类型)。
-
iLogtail 通过 LoadConfig 将配置传递给 base。
-
Base 应用配置并启动配置,从指定的数据源获取数据。
-
Base 调用 adaptor 提供的接口来进行数据递交。
-
Adaptor 将 base 递交的数据通过回调直接交给 iLogtail。
-
iLogtail 将数据加入发送队列,发送到 LogHub。
系统组成及设计
本节我们将聚焦于 libPluginBase,对插件系统的整体架构以及一些系统设计进行介绍。
整体架构

如上图所示,插件系统目前的主体由 Input、Processor、Aggregator 和 Flusher 四部分组成,针对每一个配置,它们之间的关系:
- Input: 作为输入层,一个配置可以同时配置多个 input,它们可以同时工作,采集所得到的数据将递交给 processor。
- Processor: 作为处理层,可以对输入的数据进行过滤,比如检查特定字段是否符合要求或是对字段进行增删改。每一个配置可以同时配置多个 processor,它们之间采用串行结构,即上一个 processor 的输出作为下一个 processor 的输入,最后一个 processor 的输出会传递到 aggregator。
- Aggregator: 作为聚合层,可以将数据按照需要的形式进行聚合,比如将多个数据打包成组、统计数据中某些字段的最大值最小值等。类似 input,一个配置可以同时配置多个 aggregator 来实现不同目的。Aggregator 可以在新数据到来时主动地将处理后数据递交给 flusher,也可以设置一个刷新间隔,周期性地将数据递交给 flusher。
- Flusher: 作为输出层,将数据按照配置输出到指定的目标,比如本地文件、iLogtail(通过 adaptor 的接口)等。一个配置可以同时配置多个 flusher,从而一份数据可以同时输出到多个目标。 除此以外,插件系统还提供了 Checkpoint、Statistics 和 Alarm 三部分内容,分别负责提供检查点、统计以及报警相关的功能,我们将它们进行了整体封装,以 context 的形式提供给所有插件,插件仅需调用 context 提供的接口(比如创建检查点、加载检查点、发送 Alarm 等),无需关心如何完成。对于这些功能,我们将在后文中进行介绍。
系统设计
下面我们将简单地介绍插件系统中的几点关键设计,这其中包含了一些我们在设计之初时的目标:
易扩展、易开发:使用 Go 语言实现 兼容 iLogtail 现有体系,降低用户学习成本:配置动态更新、统一 Alarm / Statistics 为插件开发提供通用功能:Checkpoint
使用 Go 语言实现
为了达到易扩展、易开发的目标,我们最终选择 Go 作为插件系统的实现语言,具体考虑的因素有以下几点:
- 并发隔离:在生产环境中,iLogtail 可能会同时运行多个插件来满足不同的采集需求,不同插件之间的隔离和并发是必须解决的问题。Go 语言面向并发程序的设计使得我们能够较为简单地实现隔离和并发的需求,从而在开发 iLogtail 插件时,开发者可以更关注于自身逻辑,而无需关心系统整体。
- 动态加载:由于 iLogtail 已经有不小的装机量,使用动态加载来尽可能隔离插件系统,降低对 iLogtail 主体的影响也是我们考虑的因素之一。Go 原生支持生成为动态库可以很好地满足我们的需求。
- 贴近社区:目前 Telegraf 以及 Beats 这两个开源 Agent 均采用 Go 实现,因而使用 Go 能够使得我们的插件系统更加贴近社区,降低社区开发者的学习难度。
- Go plugin:我们也在观望着 Go plugin 的进展,一旦觉得时机成熟,通过 Go plugin 来实现完全地动态扩展将能够更好地为用户提供助力。
- 易开发:Go 语言的开发效率在一般情况下都高于 iLogtail 所采用的 C++,更适合插件这类需要快速开发的场景。
动态更新配置
目前,日志服务支持通过控制台进行采集配置,然后自动下发到 iLogtail 进行应用执行,当配置发生变化时,iLogtail 也会及时地获取这些配置并进行动态更新。插件系统作为配置内容的一部分,同样要具有这种动态更新配置的能力。
在插件系统中,我们以配置为单位对插件进行了组织,每个配置实例根据配置的具体内容,创建并维护其中的 input、processor 等插件的实例。为了实现这种动态更新配置的能力,libPluginBase 提供了相应的 HoldOn/Resume/LoadConfig 接口进行支持,更新流程如下:
- iLogtail 检查配置更新的内容是否有关于插件系统的更新,如果有,调用 HoldOn 暂停插件系统;
- 插件系统执行 HoldOn 时,会依次停止当前的所有配置实例,这个过程中会存储必要的检查点数据;
- 在 HoldOn 调用完毕后,iLogtail 通过 LoadConfig 加载发生更新或者新增的配置,这个调用会在插件系统内创建新的配置实例,新实例会覆盖之前的实例。 此处为了避免数据的丢失,新创建的实例会将被覆盖的实例中的数据进行转移过来,从而在恢复后能够继续处理这些数据;
- 当配置更新完毕后,iLogtail 调用 Resume 恢复插件系统的运行,动态更新配置完毕。
统一 Statistics、Alarm
在 iLogtail 中,为了更好地帮助用户进行统计数据分析和问题排查,我们实现了 Statistics 和 Alarm 机制。插件系统同样会有这样的需求(每一个插件在运行期间都可能会产生各自的统计或报警数据),对此,我们希望能够与 iLogtail 现有的 Statistics 和 Alarm 机制进行统一。因此,在独立于用户配置之外,我们构造了两个全局的配置,分别用于接收来自其他配置内插件的 Statistics 和 Alarm 数据,然后统一输出。
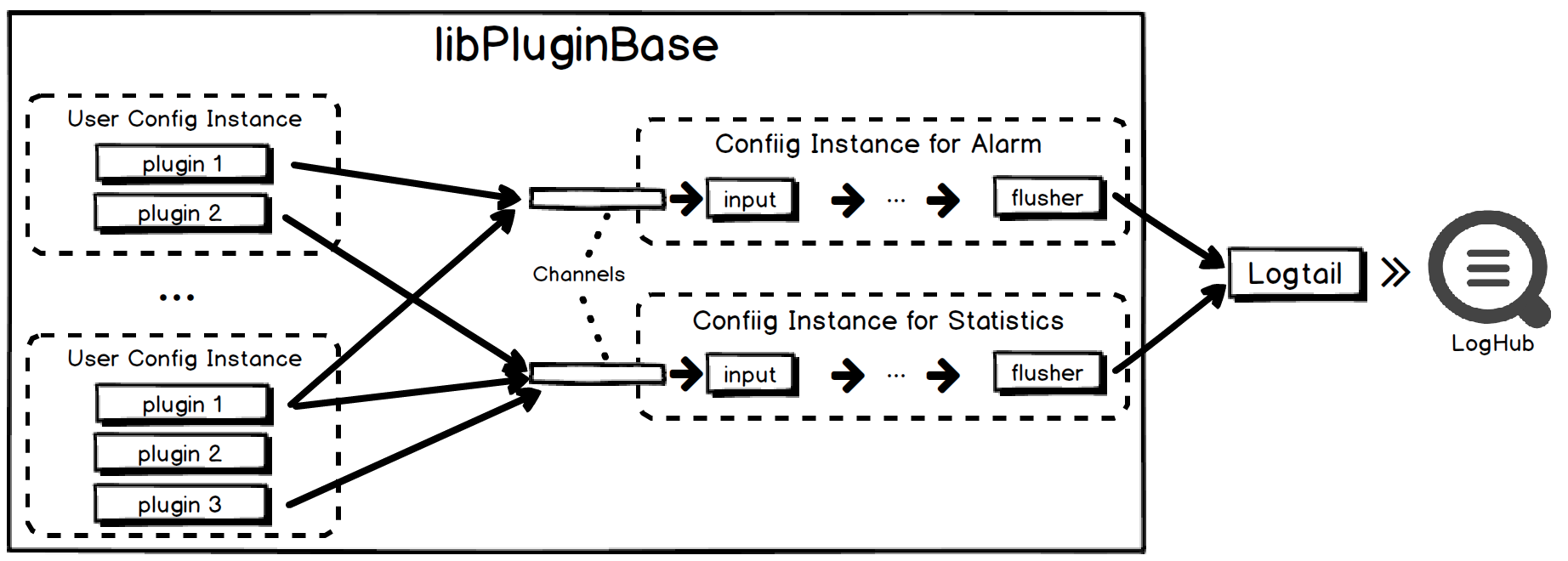
如图所示,右侧是两个独立的全局配置实例,分别对应于 Statistics 和 Alarm 的接收和输出,它们采用和用户配置一样的结构,入口处使用一个内置的 input 插件从 channel 中读取数据,经过中间的处理传递,将数据交由 flusher 插件输出到 iLogtail。左侧的用户配置实例中的任意插件都可以根据自身逻辑输出统计或报警数据,通过 Go channel 发送给右侧的全局配置实例。
Checkpoint
在实现采集 Agent 的过程中,为了保证在崩溃、更新、重启等情况下不丢失数据,一般都会通过记录检查点来维护采集进度。对于部分插件而言,这同样是一个必需功能,比如 MySQL Binlog 插件要记录自己当前采集的 binlog 文件名以及偏移量。因此,我们在插件系统中实现了通用的检查点功能,通过 context 输出相应的键值 API 供插件使用。
type Context interface { SaveCheckPoint(key string, value []byte) error GetCheckPoint(key string) (value []byte, exist bool) SaveCheckPointObject(key string, obj interface{}) error GetCheckPointObject(key string, obj interface{}) (exist bool)
# ...}