日志采集效能跃迁:iLogtail 到 LoongCollector 的全面升级
iLogtail 发展简史回顾
●2013年,iLogtail的第一个版本就随着飞天5K系统上线。飞天5K项目是一个调度5000台计算机合力为一个超级计算机的分布式操作系统项目,当时研发iLogtail的目的也很简单,将分散在几千台机器上的日志数据统一收集到一个中心数据仓库中,方便查阅和分析。在这一阶段,iLogtail的技术投入重点是基础日志采集,典型的技术功能点有通过inotify感知日志变更实现日志实时采集、飞天日志解析完成结构化、实时将日志发送到远端存储、基础的自监控日志上报等。
●2015年,阿里巴巴开始推动集团业务上云,大家所知道的2019年双11宣布核心系统全面上云,其实这一过程从2015年就已经开始了。在这一过程中,iLogtail的用户从阿里云扩展到整个集团,对其处理能力的丰富程度和稳定性就提出了更高的要求,iLogtail也在这种背景下打磨出了一身过硬的本领,比如帮助故障隔离的高低水位反馈队列、防止日志丢失的checkpoint机制、多租户管理能力以及更丰富的日志处理能力。
●2017年,随着SLS的正式商业化和ACK服务上线,iLogtail的用户数呈现几何级增长,新的需求如雨后春笋般涌现,同时iLogtail的使用场景也从主机扩展到了容器。为了适应新环境的变化,iLogtail演化出了Go插件系统,在这一子系统的加持下,iLogtail迅速支持了容器日志采集、K8s元信息自动打标等功能,同时也开始往时序、追踪数据的接入开始迈进。
●在2022年,iLogtail正式向外界完整开源,并且将版本提升到1.0.0,这也标志着iLogtail的技术成熟,从一个单一的日志采集器蜕变为功能完整的可观测数据采集器。1.0系列实现了对常见容器运行时的完整支持,适用于云原生环境,同时在开源社区同学的努力下,丰富了其对下游生态的输出支持,同时紧跟时代步伐,增加了对可观测性数据的第四根柱子——Profiling的数据接入支持。
●2024年,在iLogtail开源两周年之际,iLogtail发布了2.0.0版本,该版本结合社区贡献、顺应市场变化在易用性、性能和可靠性方面,相对1.0系列版本均有显著提升。

从 iLogtail 到LoongCollector,不只是重命名
在 2025 年,iLogtail 正式升级成为 LoongCollector,这一转变标志着我们在日志采集和处理领域迈入了一个新的时代。LoongCollector 在日志场景中实现了全面的重磅升级,从功能、性能、稳定性等各个方面均进行了深度优化和提升,从而为用户提供了更为高效、灵活和可靠的日志管理解决方案。接下来,我们将对 LoongCollector 的升级进行详细介绍。

基础巩固——高性能、灵活 Pipeline 流水线
基础介绍
对iLogtail进行整体的架构升级,尤其是C++主程序部分,通过引入流水线的概念,将输入、处理和输出能力彻底插件化,支持能力的自由组合,从而满足上述需求。有关架构升级的部分内容,可参考《破浪前行:iLogtail十年老架构如何浴火重生》。
在LoongCollector中,每一个采集任务都对应了一个采集配置,它描述了如何采集、处理和发送所需的可观测数据。在代码实现上,每一个配置都对应于内存中的一条流水线,其通用形态如下所示:

LoongCollector 目前支持的 Pipeline 形态多样化,旨在满足不同用户的日志采集和处理需求,灵活适配多种应用场景。具体支持的 Pipeline 形态包括:
●C++ Input 插件 + C++ 原生处理插件
这种组合允许用户利用 C++ 的高性能特性进行日志数据的输入和处理。这种方案特别适合需要实时处理大量日志的场景,能够显著降低延迟并提升性能。
●C++ Input 插件 + SPL 处理插件
SPL(SLS Processing Language) 处理插件则提供了一种直观且强大的方式进行数据分析和处理。这种组合不仅提升了处理复杂性的能力,同时也简化了用户的操作体验。
●C++ Input 插件 + Golang 拓展处理插件
通过结合 C++ Input 插件与 Golang 拓展处理插件,用户可以充分利用两者的优势。C++ 插件在数据采集过程中提供高性能的采集能力,而 Golang 插件则为数据处理增添了灵活性。
●Golang Input 插件 + Golang 拓展处理插件
Golang Input 插件最大的优势是支持多种数据源,包括 Systemd、 Kafka、Win event 等,这种组合可以最大程度上适配多种多样的数据源。

流水线配置热加载隔离
LoongCollector采用总线模式,按功能划分线程。具体来说,根据流水线的形态,LoongCollector共有三大工作线程:Input Runner线程、Processor Runner线程和Flusher Runner线程,分别负责运行所有流水线的输入插件、处理插件和输出插件,各个线程之间通过缓冲队列进行连接。为了保证流水线之间的公平性和隔离性,LoongCollector进一步采用如下设计:
●在每一个工作线程内,每一条流水线都按照优先级分配了相应的时间片;
●每个流水线都拥有自己独立的处理和发送队列。
基于上述描述,LoongCollector的总线模式示意图如下:

但是总线模式,势必也对多租场景的隔离带来更大的挑战。从线程方面进行隔离是最简单的,但是多线程势必带来资源占用的成倍增长,这个是作为可观测数据采集器无法接受的。LoongCollector 在采集配置整体调度,Flusher 线程资源分配的调度上,进行了深度优化,在总线模式下,最大程度上保证了多租能力。
iLogtail 在采集配置变更的情况下,采用的是 Stop The World 的方式,所有采集配置全部暂停,重新加载,然后重新启动。这样子在多个团队或者多个业务共用一个 iLogtail 实例的情况下,会有相互影响。比如业务 A 和业务 B 共用一个 iLogtail 实例,业务 A 的同学在不断调试采集配置,在调试阶段必然会对业务 B 的采集产生一定的影响。

LoongCollector 对流水线的生命周期管理进行了进一步优化,只对于有变化的 Pipeline 采用新旧替换的方式,其他没有变化的 Pipeline 保持不变,最大程度上保证采集配置变更影响最小化,避免 Stop The World 对整体的影响。
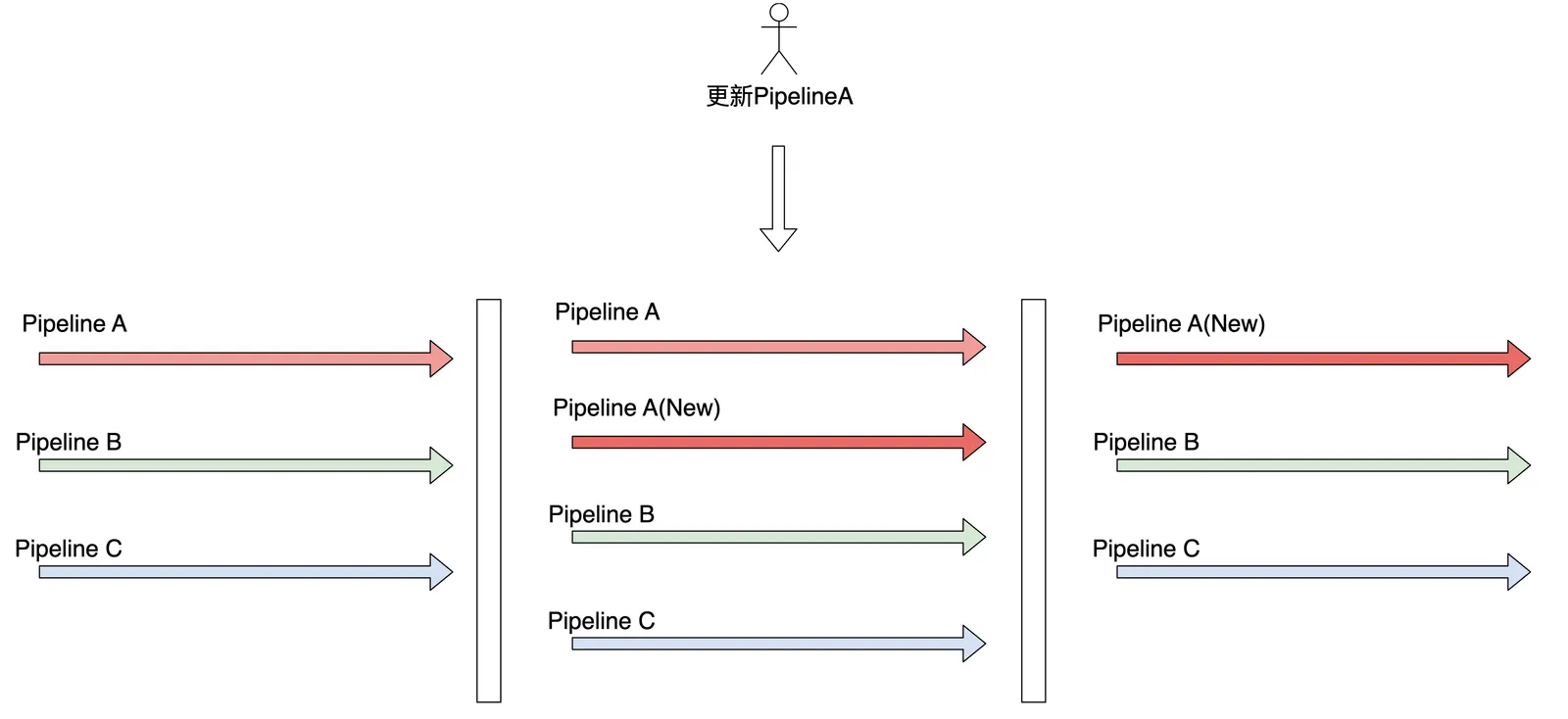
持续突破——核心场景采集性能不断提升
CPU 平均降低 35%,内存平均降低 10%
极简单行模式下,相同流量资源使用比较(柱值越低越好)


可以看到无论是 CPU 还是内存,LoongCollector 相比 iLogtail 都有比较大的优势。尤其是 CPU,LoongCollector 比 iLogtail 平均降低 0.15C;内存的话,在低流量场景,LoongCollector 优势不太明显,但是在高流量场景下,内存占用降低 10%左右。
核心场景极限采集速率平均提升 80%
文件采集


由图可以看到,在典型文件采集场景下, LoongCollector 无论是单线程还是多线程的场景下,采集性能对比 iLogtail 都有非常大的提升,单线程平均提升 40%,极简场景下提升 80%;多线程场景下提升更加明显,平均提升 80%
标准输出
●通过重构标准输出采集插件,推出了新版插件 input_container_stdio,该插件支持日志轮转队列,显著增强了标准输出采集的稳定性。
●在性能方面,新插件表现优异,在 containerd 运行时场景,采集性能提升 200%;docker 运行时场景,采集性能提升 100%。

●资源占用方面,containerd 场景,新插件 CPU 资源占用降低 20%,内存降低 25%;docker CPU 降低 25%,内存降低 20%。


稳定性升级——更好的自监控
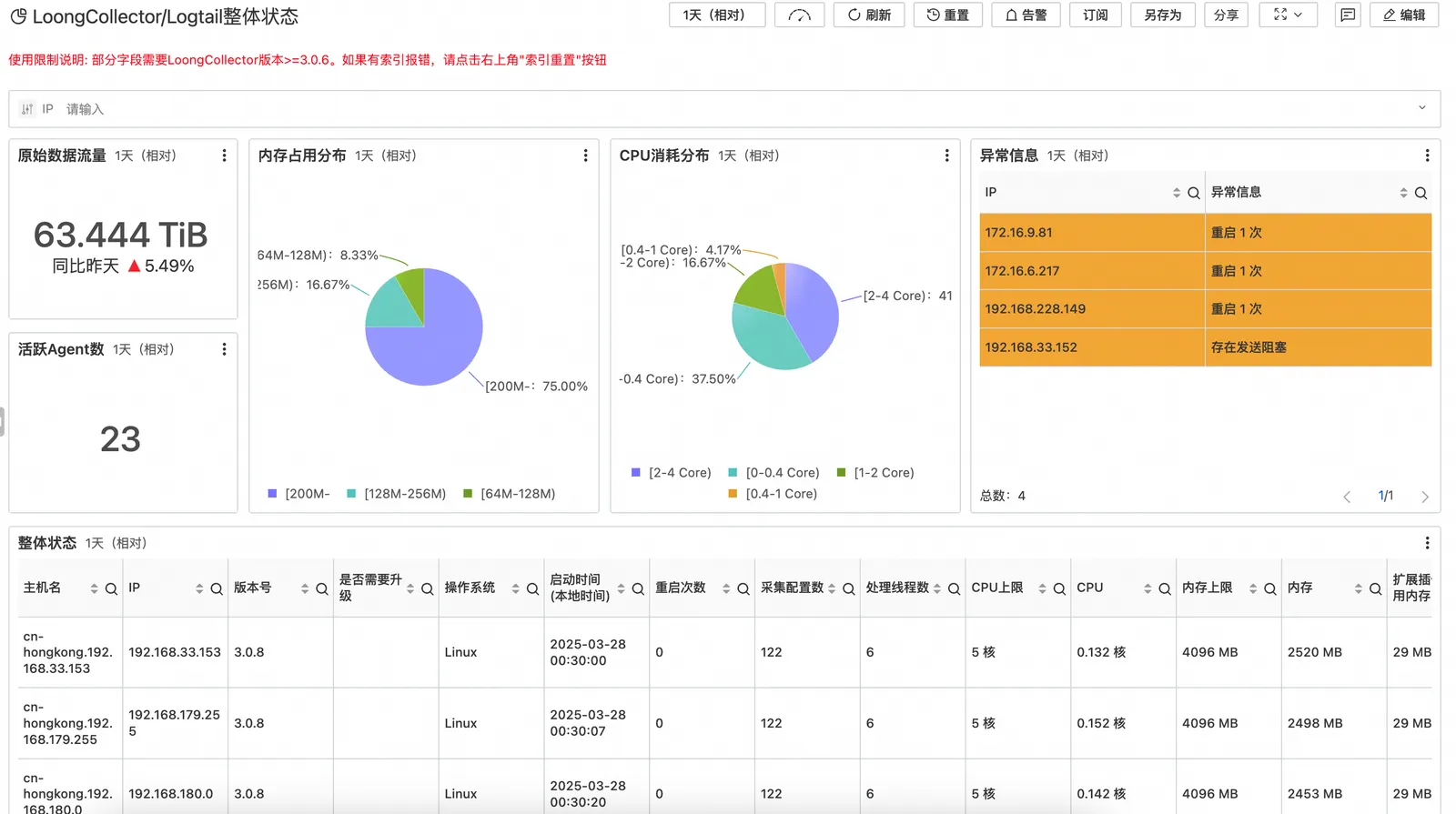
LoongCollector 实例监控
提供了全面的实例监控功能,确保用户能够清晰地掌握系统资源的占用情况和实例的异常信息。通过直观的监控仪表盘,用户可以实时查看 CPU、内存和网络等资源的使用情况,使得每个实例的运行状态一目了然。系统还能自动触发告警,及时通知用户异常事件,帮助用户迅速定位问题并进行处理。
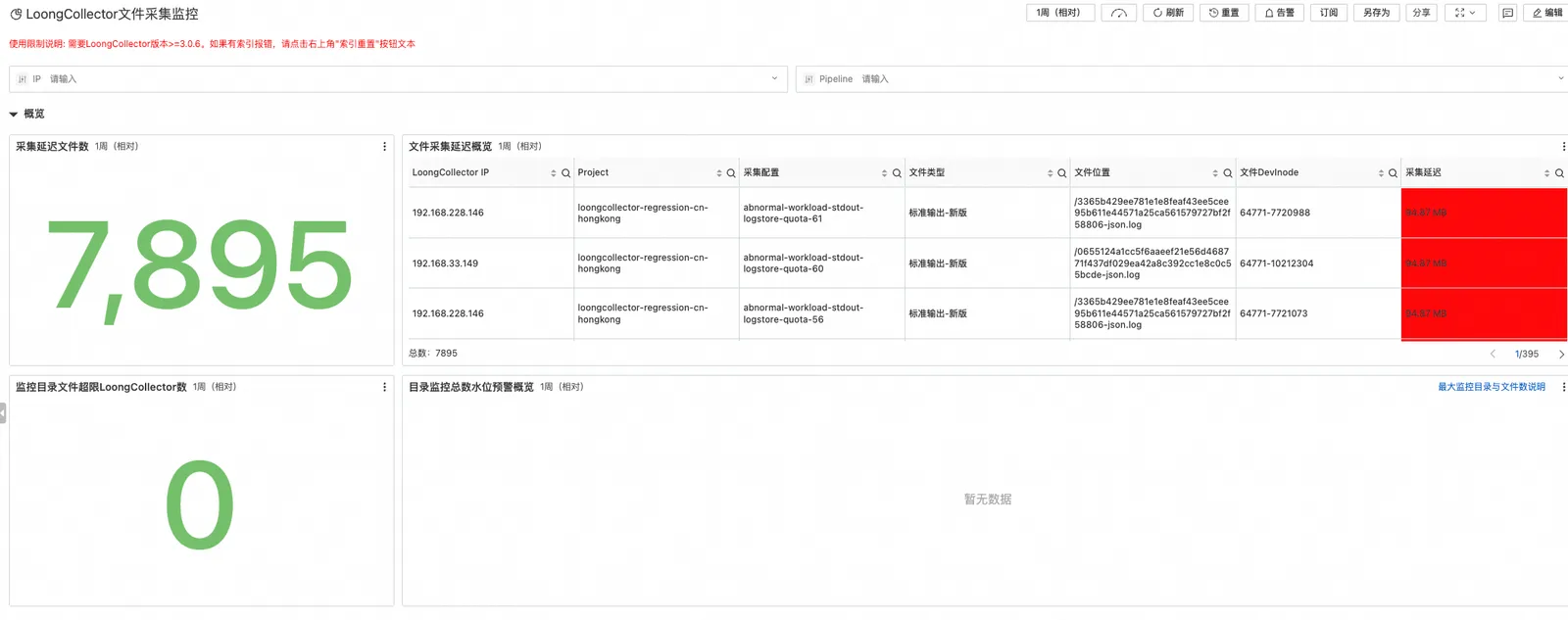
文件采集监控
在文件采集场景中,LoongCollector 具备强大的数据监控能力,包括对采集目录水位和采集延迟的全面监控。用户可以在概览页面快速了解各个目录的当前文件数量等关键信息,以便于及时发现潜在的文件积压问题。同时,在详情页面中,我们的自监控也提供了更深入的分析功能,帮助用户识别文件采集过程中的延迟问题。
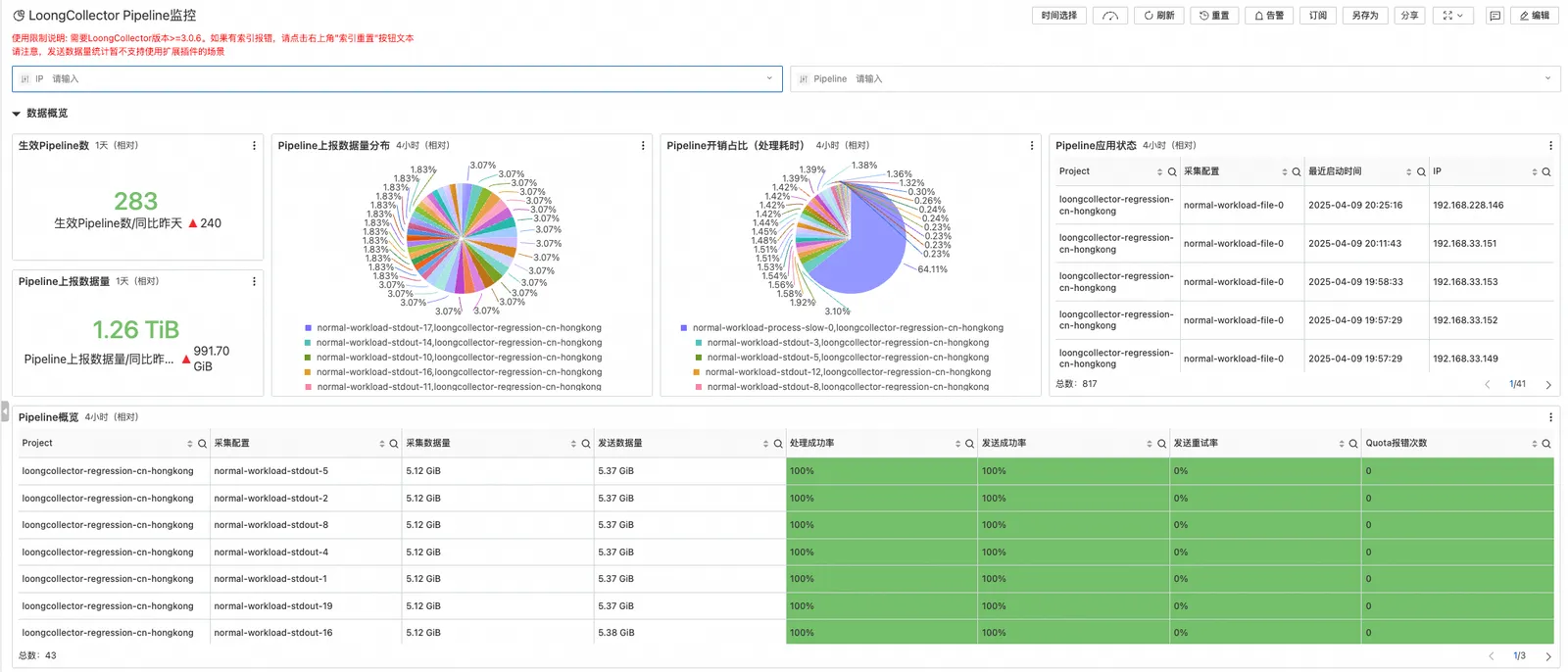
Pipeline 详情监控
针对多采集配置场景,LoongCollector 的 Pipeline 详情监控功能全面展示了各个采集配置的耗时、异常信息等关键数据。用户可以在该部分监控界面中清晰地看到每个 Pipeline 阶段的处理时间,从而轻松识别性能瓶颈和潜在优化点。同时,自监控也会记录在各个步骤中发生的异常,帮助用户快速定位问题并进行调整。通过对 Pipeline 过程的深入监控和分析,用户能够更有效地优化日志采集和处理策略,提升整个日志处理系统的性能与可靠性。
网络异常隔离——容忍单 AZ 网络异常
总线模式下的另一个隔离性问题就是流水线的发送异常隔离。例如,对于SLS输出插件而言,当某个地域的网络出现异常时,会导致所有配置了SLS输出插件且发送目标为该地域的流水线出现发送受阻。在总线模式下,由于Flusher Runner线程是全局共用的,不论流水线是否发送异常,它都会从发送队列中取出待发送数据并推送到Sink队列中。因此,来自于发送异常的流水线的请求会被反复尝试发送,从而占用有限的网络IO资源,影响其他正常流水线的发送。
为了实现总线模式下的流水线发送异常隔离,我们在 LoongCollector 上增加了一个流量分配机制来控制Flusher Runner线程从发送队列中获取数据的行为。

从整体按照三个维度进行流量控制:AZ、Project 和 Logstore
●AZ 限流,处理网络问题/服务端问题
●Project 限流,处理Project Quota问题
●Logstore 限流,处理Shard Quota问题
每一个限流器都采用的是自适应限流算法,参考网络拥塞控制算法AIMD(Additive Increase, Multiplicative Decrease),当出现发送失的时候,会快速降低发送并发度,当出现发送成功的时候,会逐步提高并发度。为了避免网络抖动带来的异常,统计过去一段时间/一批数据的发送情况,避免并发毒频繁抖动。
通过使用这个策略,能够保证某个发送目标出现网络异常时,该目标允许发送的数据包可以快速衰减,最大程度减少该发送目标对其他发送目标的影响。如果是网络中断场景,则休眠期的做法能够最大限度减少不必要的发送,同时当网络恢复时,也能在有限的时间内及时恢复数据发送。
如下示例,在使用 LoongCollecter 将采集数据同时对地域 A 和地域 B 进行多地域发送的情况下,地域 B 的网络异常,对于地域 A 的数据采集、发送不会有任何影响。

网络质量自动探测——从容应对网络波动
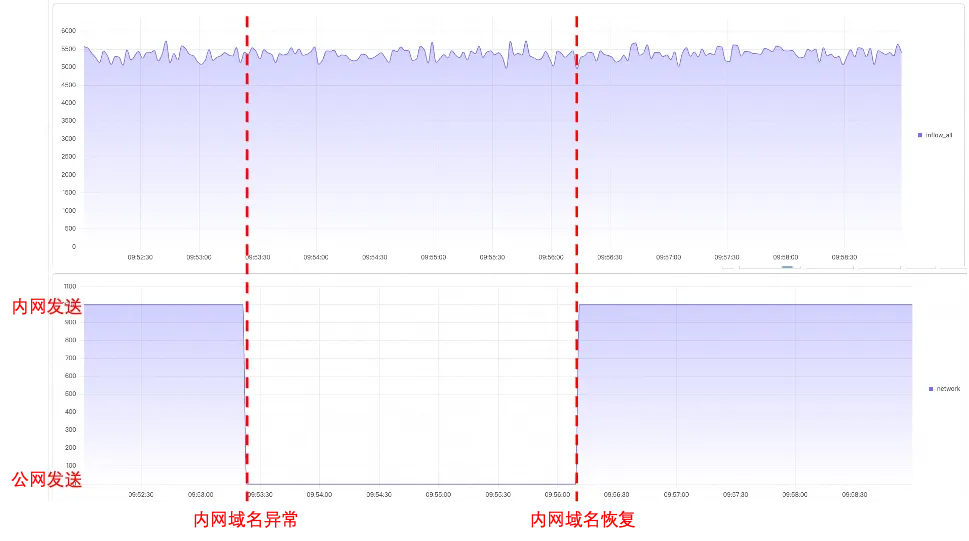
SLS 的域名分为内网和公网域名, 如果固定内网域名,那么一旦内网网络出现问题,数据发送会受阻。LoongCollector 考虑到这种情况,会自动对 SLS 域名网络质量进行探测,一旦发现网络质量很差,那么就会自动切换到另一个域名上。
如下图所示, 正常 loongcollector 发送数据是走内网发送,然后内网异常之后,loongcollector 会自动切换到公网域名进行数据发送,等待内网恢复之后,loongcollector 还会自动切换回内网域名,这样保证了单网络异常情况下的数据发送稳定性。从流量图上看,域名切换基本没有流量波动。
无忧迁移——完整的、无中断存量迁移方案
主机场景无缝从 iLogtail 升级到 LoongCollector
支持从 iLogtail 无缝升级到 LoongCollector,参考升级文档。之前的采集配置、checkpoint 等不会丢失,从感受上跟重启一次没有区别,LoongCollector 完全兼容 iLogtail 的所有配置内容。
K8s 场景无中断升级
组件资源级别升级管理
●组件级别卸载重装,必定会有一段时间服务不可用
●资源级别控制,可以保证服务不可用的时间降低到最小
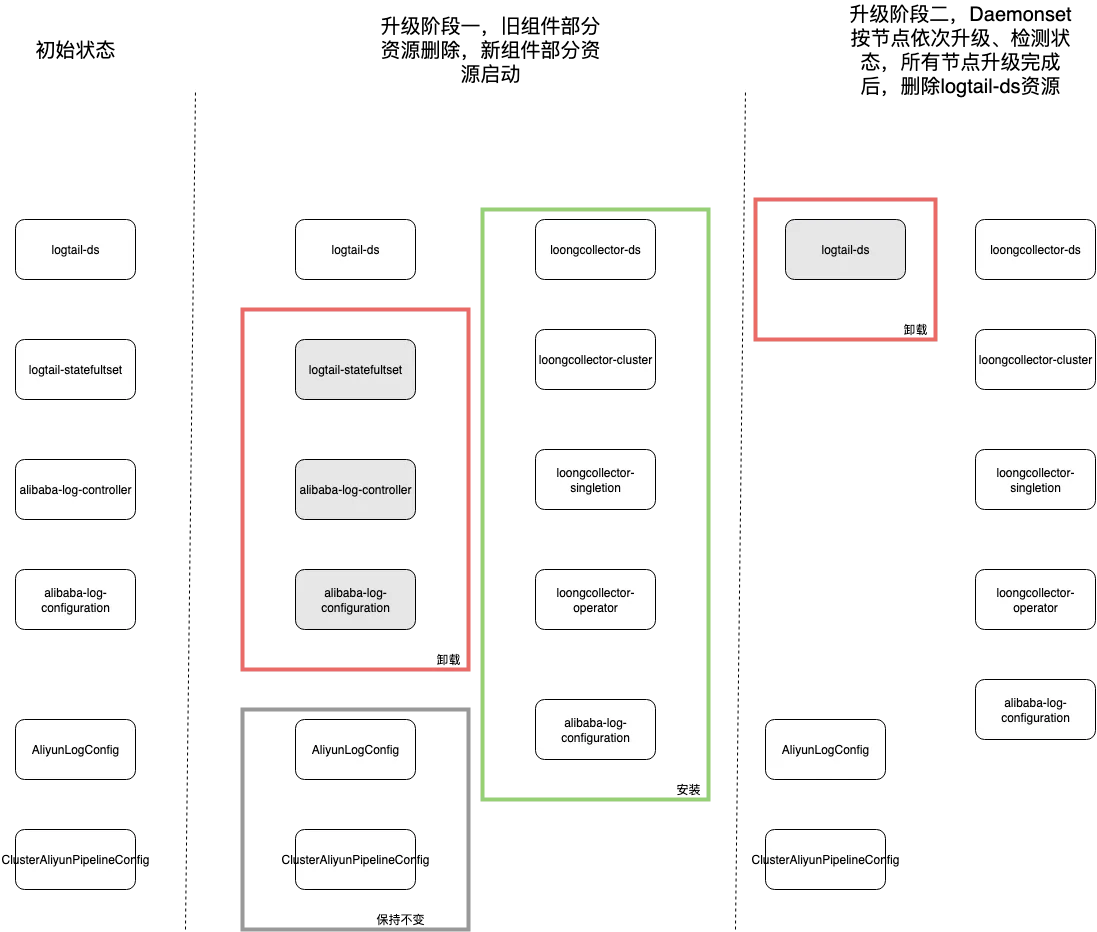
采用亲和性控制,实现 Daemonset 从 logtail-ds 无缝切换到 loongcollector-ds
可达到的效果如下图所示:

单节点如何保证数据不丢失、不中断
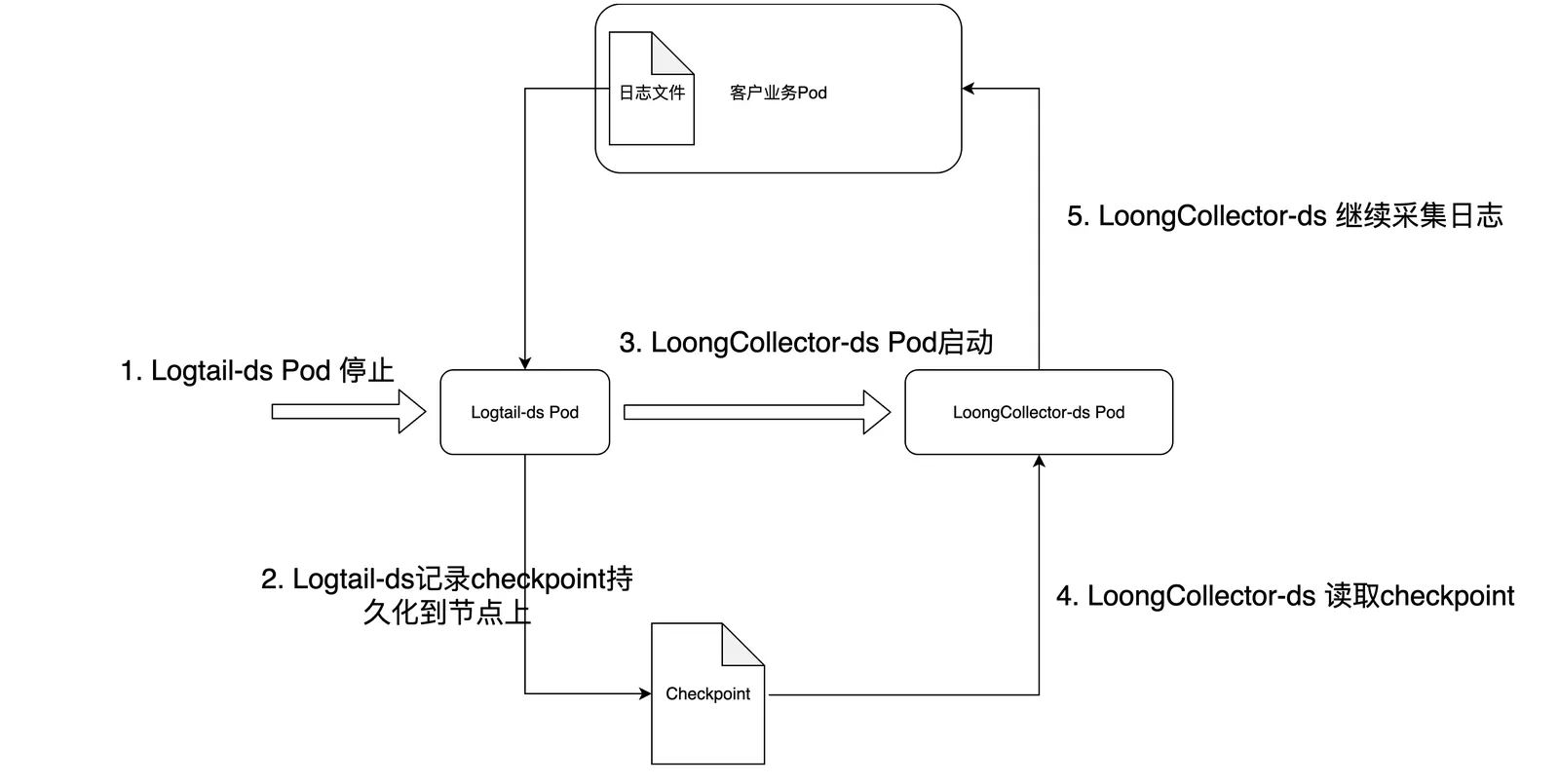
Logtail-ds 由于本身具有 checkpoint 机制,单节点 logtail-ds 停止的时候,会将文件采集的 offset 信息持久化到节点的 checkpoint 中;LoongCollectore-ds 启动的时候,会先从checkpoint 中读取 offset,然后继续从 offset 处开始采集,从而保证数据不重复、不丢失。
K8s 组件升级效果

可以看到在组件升级前后,无论是标准输出采集还是文件采集,数据趋势非常平稳,没有数据中断与数据重复。
全新 Tag 处理能力 —— 从杂乱无序到统一处理
Tag 标签是 iLogtail 日志采集标识日志元信息的重要数据,但是iLogtal针对标签数据的处理存在一定的问题
●标签数据来源不一致:对于大部分元信息,Logtail会默认在tag里添加;对于少量其他元信息(如inode),通过流水线配置里的布尔参数来决定是否要在tag里添加。
●用户无法对 tag 进行重命名和删除操作。
●C++和Go对 tag 的处理机制完全不同,没有统一的方案
LoongCollector 为了解决上面的问题,对于标签处理进行了整体的优化。
●Input 级别的标签数据由各个 Input 插件单独处理、控制
●容器场景,新版标准输出采集插件所有标签跟文件采集完全一致
●支持使用标签处理插件进行实例级别元信息的添加、删除和重命名操作;C++和Go 标签处理功能完全一致,保证所有流水线类型均可以使用完整的 Tag 处理能力
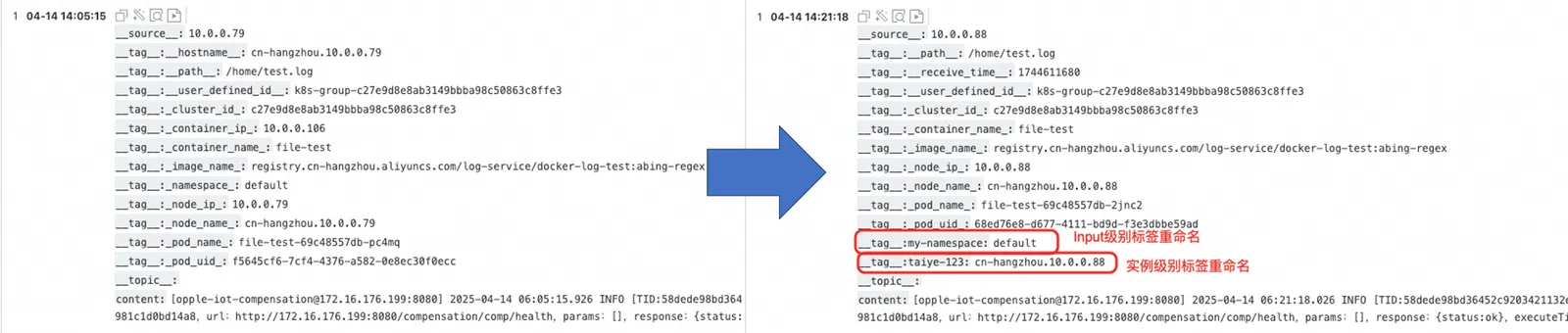
比如我采用如下配置,分别对文件 Input 的标签和实例级别标签进行处理
{ "configName": "taiye-file-test-new", "inputs": [{ "Type": "input_file", "FilePaths": [ "/home/**/test.log" ], "EnableContainerDiscovery": true, "CollectingContainersMeta": true, "ContainerFilters": { "IncludeEnv": { "aliyun_logs_taiye-file-test": "/home/test.log" } }, // Input 标签处理 "Tags": { "K8sNamespaceTagKey": "my-namespace", "ContainerIpTagKey": "" } }], "flushers": [{ "Type": "flusher_sls", "Endpoint": "cn-hangzhou-intranet.log.aliyuncs.com", "Logstore": "taiye-file-test-new", "Region": "cn-hangzhou", "TelemetryType": "logs" }], "global": { // 将 HOST_NAME 标签重命名 "PipelineMetaTagKey": { "HOST_NAME": "taiye-123" }, // 开启实例标签处理 "EnableProcessorTag": true }}可以看到 tag: namespace 和 tag: hostname 标签被正确重命名,tag:container_ip 标签被正确删除
What’s More —— LoongCollector 即将带来可观测数据全栈采集新体验
LoongCollecoter 以 iLogtail 高性能 Pipeline 为底座,将 Prometheus 指标采集、eBPF 采集等融入 iLogtail 采集流水线中,实现采集能力的全面升级,做到可观测采集的 OneAgent 化。更多能力即将解锁,敬请期待。
参考资料
当 Prometheus 遇到 C++,我们如何实现下一代指标采集探针
从iLogtail到LoongCollector——解读架构通用化升级中的性能优化秘籍