阿里云全面拥抱 OpenTelemetry 的历程
以下文章整理自 KubeCon China 2024,原文链接:https://kccncossaidevchn2024.sched.com/event/1eYcJ/opentelemetry-community-update-opentelemetrytuo-zihao-rao-huxing-zhang-wanqi-yang-alibaba-cloud-jared-tan-daocloud
我是来自阿里云可观测团队的望陶,今天我将介绍阿里云全面拥抱 OpenTelemetry 的演进历程。首先先简单介绍下阿里云内部可观测平台的演进历程。
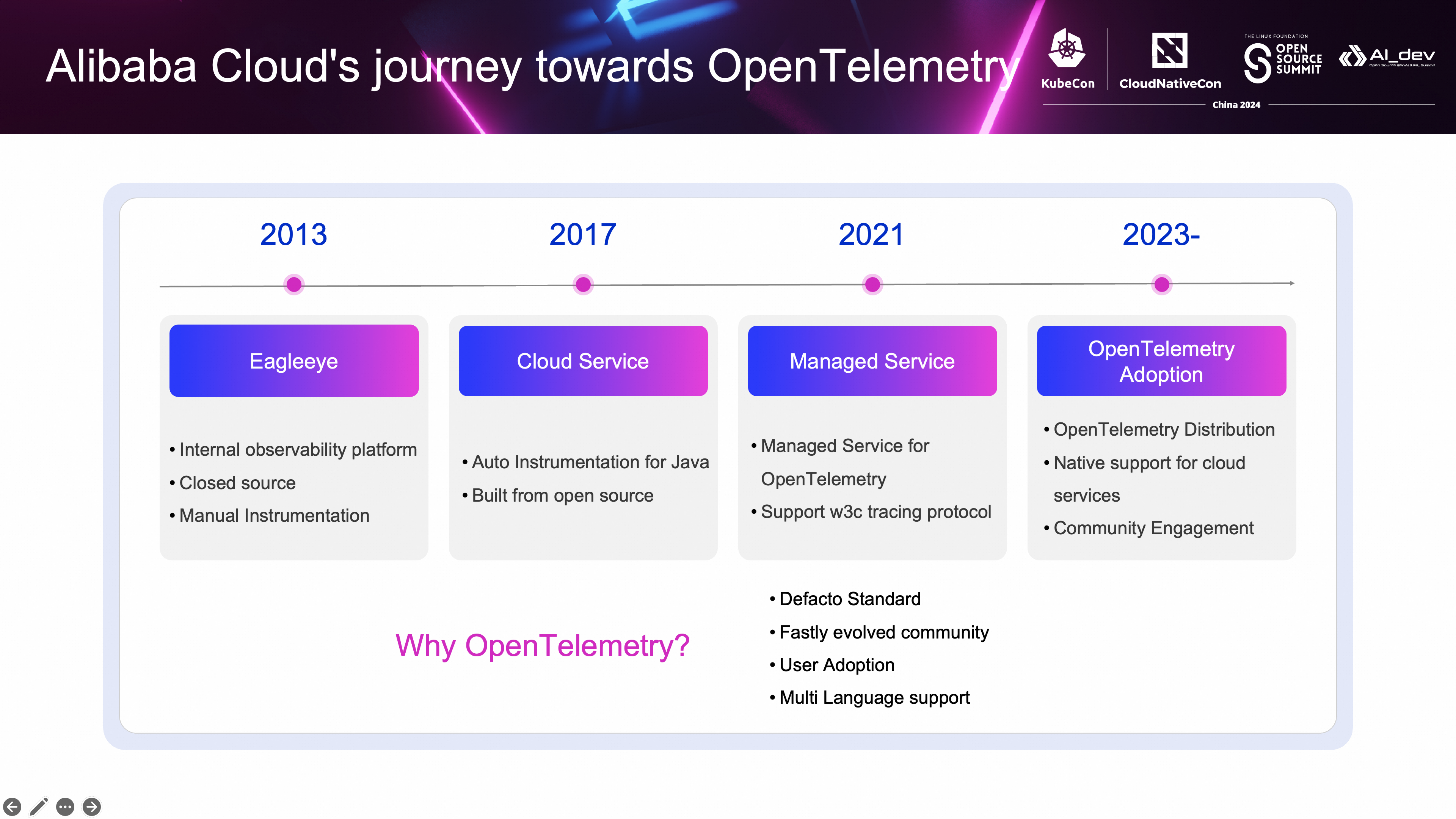
在 2013 年,在阿里内部上线第一代可观测平台,内部名称代号为 Eagleeye,参考当时 Google 提出的 Dapper 论文的思想,当时主要专注在分布式链路追踪以及指标的收集的领域,在内部得到了广泛的使用,包括支撑了历年的双 11 大促,对于问题的诊断起到了非常重要的作用。当然,这个平台是闭源的,在当时采用了手动埋点的方式,不过我们针对主流中间件(例如 HSF/Notify/TDDL )的支持,采用了 Pandora 的方式,Pandora 是一个轻量级的业务隔离容器,将中间件和业务的代码和依赖通过不同的类加载器进行隔离,业务只需要升级 Pandora 包,就可以引入 Eagleye 提供的链路追踪和指标的能力。
在 2017 年,阿里云上线了第一款应用性能监控 APM 的产品 ARMS (应用实时监控服务),在那个时候我们认为对于客户来说,低成本的接入非常重要,因此针对 Java 应用推出了自动埋点的接入方案,当时基于开源的 Pinpoint 开发了第一代的 Java 探针。
在 2019 年,随着 OpenTelemetry 项目的成立,越来越多的公司开始参与到这个项目中,该项目迅速演变成为可观测数据采集的事实标准,随之而来的是越来越多的用户开始采纳 OpenTelemetry,并且希望阿里云能够提供对 OpenTelemetry 的支持,因此在 2021 年,阿里云也推出了 OpenTelemtry 的托管服务,允许客户将 OpenTelemetry 客户端采集到的数据发送到服务端,并完成链路追踪和指标聚合及展示等工作,客户无需对数据进行存储、加工、处理,大大提升了针对可观测数据运维的效率。
采纳 OpenTelemetry 带来的另一个好处是,提供了多语言的支持,曾经有一段时间阿里云也推出过自研的 PHP 探针,但是因为私有的数据格式和协议、缺乏持续的维护,带来不少的问题,需要较高的维护成本。OpenTelemetry 改变了这一现状,提供了市面上常用语言的埋点方案,需要语言甚至也提供了自动埋点的方案,这大大降低了维护多种语言探针的成本。
但这还远远不够,从 2023 年开始,全面拥抱 OTel 提升到更高的优先级,这表现在如下几个方面:
- 发布了基于 OpenTelemetry 的发行版,这包括 Java,Go 和 Python 的探针。
- 全面推动阿里云产品原生支持 OpenTelemetry。
- 全面积极的参与贡献 OpenTelemetry 社区。
即下来将进行更加详细的阐述。
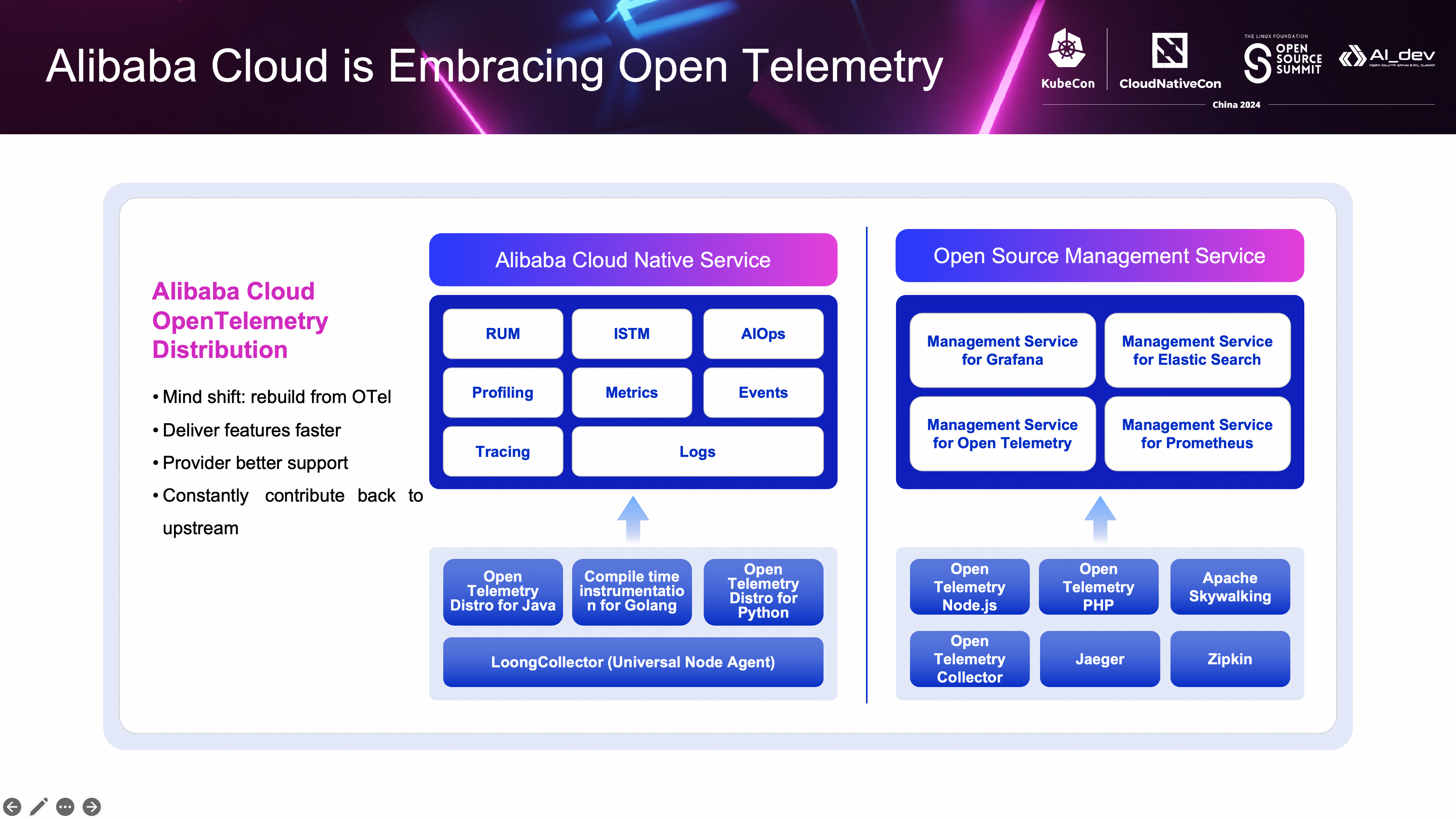
为什么推出阿里云 OpenTelemetry 发行版?这背后的核心原因我认为是思维方式的转变,OpenTelemetry 的横空出世,改变了我们构建可观测平台的方式,以至于一个产商过去所构建的平台的思路,实现方式等都需要重新进行设计,以便能够全面兼容 OpenTelemetry。因此我们做这个决策,也是基于这样的考虑,针对过去我们做的 Java 探针,基于 OpenTelemetry Java 探针重新开发了 Java 探针,而对于一些新的应用场景,我们考虑直接基于 OpenTelemetry 的已有实现进行构建,在这个过程中需要注意的是,持续的的上游社区沟通显得至关重要,为了确保后续的代码能够比较容易的合并,尽量采用扩展的方式来实现自己的代码,然后尽可能的把公共的部分的功能合并到上游社区。然后针对 Go 语言,我们推出了编译期注入的方案,这个方案也是计划贡献给 OpenTelemetry 社区,有一个 issue 正在讨论中,最后针对大模型的场景,为了更好提升跟大模型的交互的观测性,我们推出了 python 探针,也是直接基于 OpenTelemetry python 探针进行构建的。
提供阿里云 OpenTelemetry 发行版可以帮助我们更快的向客户交付一些特性,同时提供更好的服务和支持,在此基础上,客户随时可以使用开源的 OpenTelemetry 探针,将数据上报到 OpenTelemetry 托管版本当中,值得注意的是,阿里云自研的服务和 OpenTelemetry 托管版本的数据是互通的,两边的链路追踪是可以串联在在一起的,这得以与大家都基于 OpenTelemetry 进行开发。接下来将针对不同语言的发行版逐一介绍。

从 2023 年开始我们开始从基于 pinpoint 的探针体系迁移到基于 OpenTelemetry 的探针系体系,在阿里云内部秉承的是统一的 Java 探针的概念,也就是说针对一个 Java 应用只挂载一个探针,能够同时实现可观测数据采集,服务治理,例如全链路灰度,限流降级,安全,例如风险组件识别,攻击防御等诸多的能力,因此我们扩展了 OTel 的 Java 探针,通过插件化的方式增加了上述新的能力,今天由于时间的原因只会介绍在可观测方面的增强。
针对调用链和指标方面,针对国内流行的 10 多个插件和框架,都进行了支持,例如 Druid,Mybatics,XXLJob,Apache Shenyu 等,其中 6 个已经贡献回社区,更多的框架支持也会陆续贡献回社区,同时针对指标层面新增了消息,数据库,RPC,定时任务等方面的多个指标,由于 OTel 官方的指标的语义约定还尚在实验阶段,接下来也很愿意把这些贡献回社区。
针对采样方面,我们增加了错,慢,异常 span 的采样能力,同时支持了自适应的采样,确保每个接口,无论调用量大或小,都能有部分请求被采样到。
针对 Profiling,新增了 CPU、内存的 Profiling 能力,采集到的 Profiling 数据能够和 traceId 进行关联,可以大幅提升慢请求的问题定位。
针对稳定性,新增了探针开销的自监控,并支持了动态配置,允许动态调整一些行为,同时对探针本身占据的资源进行限制,超过阈值可以自动降级数据采集的能力。
在完成改造之后,得益于社区的良好设计,我们发现各方面数据均有大幅度的提升,探针的启动时间降低了 30%,探针包的大小降级了 30%,探针的内存开销降低了 20%,线程的数量更是降低了 60%。

在云原生时代,Go 语言的应用变得愈发的流行,当前的 OTel 社区中针对 Go 语言应用的可观测方案,有编译时注入的方案,以及基于 eBPF 的自动注入方案,但当前的方案各自有一定的局限性导致没有办法在生产中使用,因此我们开发了一个编译时注入的方案,能够在编译阶段自动的将 OTel SDK 的代码自动注入到应用代码中。
上图展示他的工作流程,通常一个 Go 语言的应用在编译时需要经过几个阶段,编译前端,编译后端,最后生成二进制代码,我们的方案工作在编译前端的最后,首先根据编译时注入的规则,寻找恰当的埋点入口,然后会把埋点的代码注入到对应的位置上,这些代码里面包含了 OTel SDK 可以进行指标统计,调用链分析等操作。
这样的好处是不用修改用户的代码,只需要修改编译时的命令就可以完成埋点,这个方法也很好的支持了异步调用的情况下上下文的传递,我们知道 Go 语言大量的使用协程,因此需要确保 traceID 能够在协程场景下也能串起来,传统的方法需要依赖客户在编写代码的时候手动的传递 Context 对象,但并非每个业务开发都会遵照此约定,我们的实现即使在用户没有传递 Context 对象时,依然能够确保 traceID 能够正确的透传。
另外一个特性是和 OTel-SDK 的兼容性,也就是用户之前基于 OTel-SDK 已经进行过埋点,接入以后,需要能确保之前添加的自定义的 span 或者是 attribute 能够在新的方案下也依然存在,这样也能极大的降低客户进行方案迁移的成本。
该项目目前已经开源,并且发布了第一个 0.1.0-RC 版本,同时我们已经在社区发起了捐献的讨论,如果对这项提议感兴趣的话,欢迎来围观并点赞,值得注意的是社区已经有一个 InstrGen 的编译期注入的项目,我们也正在和社区讨论融合的方案。

在过去的 2 年里面,大语言模型得到了飞速的发展并不断地涌现,也有很多基于大语言模型构建的应用,经常需要与大模型进行交互,这些交互的过程需要被仔细的追踪和观察,以确保工作是符合预期的,这包括输入和输出的准确性,没有幻觉的发生,对输出进行评估等等。为了解决这个挑战,我们基于 OTel python 探针构建了阿里云 OTel python 发行版,增加了常见的大模型的埋点,以更好的观测和大模型的交互过程。在构建的过程中我们也看到 OTel 社区正在讨论中的 GenAI 语义约定,因此我们的发行版也严格的遵循了最新 GenAI 语义约定,同时支持了常见的大模型框架例如 LlamaIndex,Langchain,PromtFlow 以及 通义千问2,OpenAI 等大模型。
在社区 GenAI 规范的基础上,我们还增加了额外的精细化的埋点和 attribute,能够观测到更加细节的交互过程,包括支持 session_id 在多个 traceId 之前进行传播,以方便在一个会话中关联多个调用链。有了这些埋点之后,客户可以方便的在专属大模型视图中查看与大模型交互的信息,包括各种 RAG 的过程,调用大模型的入参出参,消耗的 token 等等,这些增强我们也计划贡献给社区。

针对 Profiling 数据,我们扩展了 OTel Java / Go / Python 发行版增加了进程内 Profiling 的能力,例如在 Java 探针中,我们和阿里云 Dragonwell 团队合作扩展 async-profiler,提供了 on-cpu 和 off-cpu 的 Profiling 能力,能够以非常低的成本,查看 CPU 热点,以及包括等待 文件IO/网络IO 的热点情况,并且能够和 trace 调用链进行关联。更重要的是,正在支持最新的 OpenTelemetry 的 Profiling 数据格式。
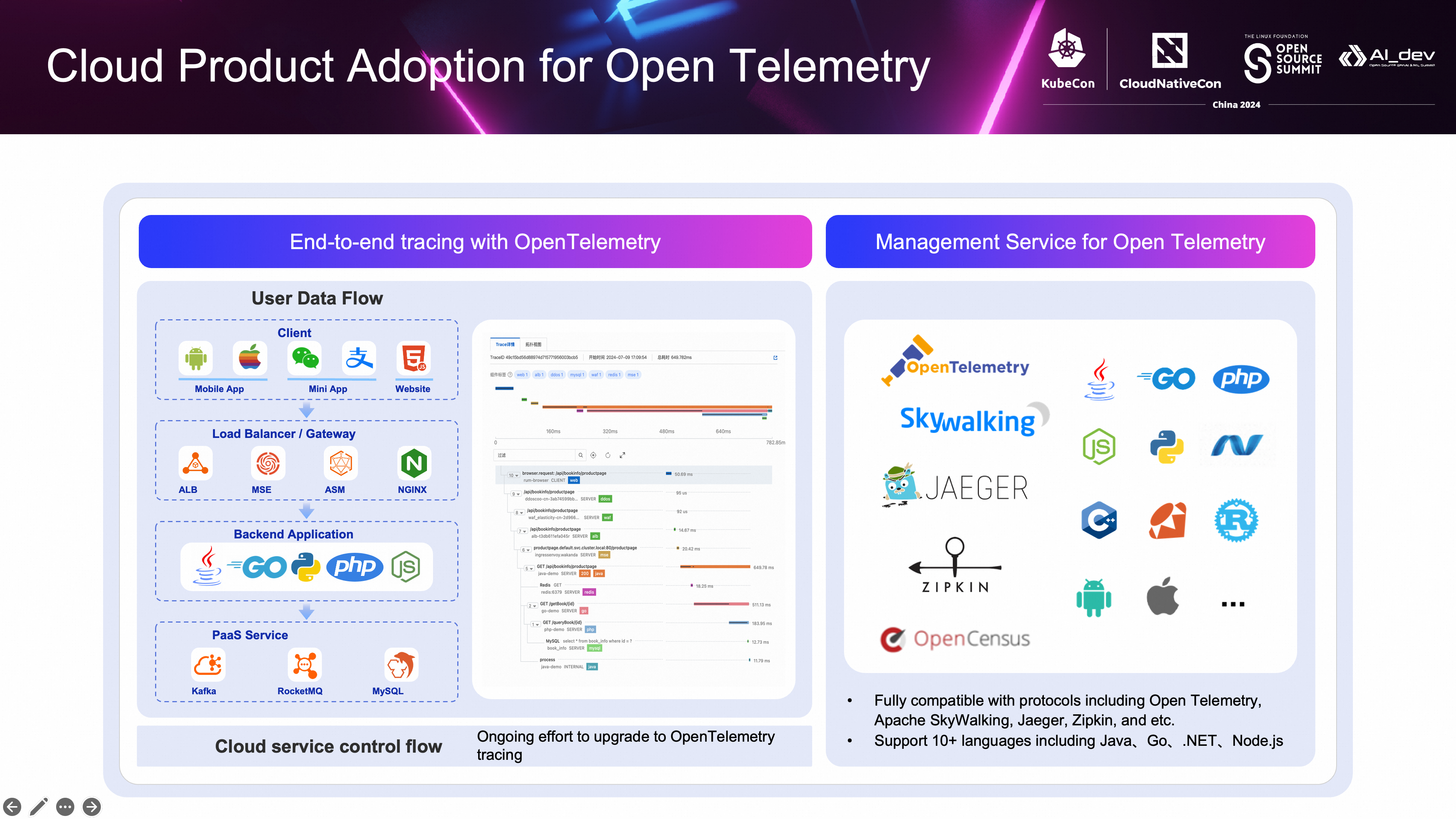
除了发布前面所提到的 OTel 阿里云发行版之外,为了面向用户提供端到端全链路追踪的能力,我们也在积极推动阿里云的产品原生支持 OpenTelemetry。从端侧例如移动端、小程序或者网页,到 ALB 负载均衡,MSE 云原生网关,ASM 服务网格,再到后端的各种语言的应用,再到 PasS 服务例如 Mysql / Redis,甚至是 AI 大模型,都能通过 OpenTelemetry 标准的 w3c traceId 协议格式将链路串起来,当然,这里的工作还在陆续推进中,还有很多云产品也在陆续接入中。
前面提到了云产品的数据流,从云产品的控制流来看,我们也在逐步升级到 OTel 发行版之中,这里主要的挑战在于如何对老版本的调用链协议进行兼容,保证链路不断,因此我们也扩展了 OTel 探针以便支持了老的协议。

关于社区发展,从过去 6 个月的数据来看,阿里巴巴在 OTel 社区的贡献度在亚太地区排名第一,由于时差原因,很多社区的会议都在国内时间的凌晨举行,因此我们推进社区设立了针对亚太地区友好的 tag-observability 月会,以及 Java SIG 双周会,同时正在捐献例如 Go 语言编译时注入探针,Java Agent 针对 GraalVM 支持等特性,同时也参与了一些社区的活动,例如在北美的 OTel Community Day 中进行了分享。在未来还将继续积极参与社区,包括语义规范,大模型可观测能力的支持等等。