iLogtail 2.0 重大升级,端上支持 SPL
1. 流式处理语言发展
- 早期流式处理概念:
- 20 世纪 70 年代,编程语言如 APL 提供了对数组的流式操作,这可以看作是流式处理语法的早期形式。
- 管道(Pipes)概念在 UNIX 系统中的引进使得可以通过命令行将一个命令的输出串联到另一个命令的输入。
- Java 的流(Stream)API:
- Java 8 在 2014 年引入了 Stream API,为集合框架提供了一套流式处理语法。
- Stream API 支持链式调用、延迟计算和内部迭代,使得流式处理与 Java 语言天然融合。
- 分布式流处理框架:
- Apache Storm 和 Apache Samza 等框架提供了面向分布式流处理的语言和 API。
- Apache Flink 和 Apache Beam 等更现代化的框架引入了支持事件时间(event time)概念和窗口化计算的复杂流式处理语法。
- 流批一体(Stream-Batch Unification):
- Apache Beam 推广了一种新的模型,它允许开发者以相同的方式处理批处理和流处理。
- 这一模型通过提供一套统一的流式处理语法和抽象,简化了在不同运行时(如Flink、Google Cloud Dataflow)上编写数据处理管道的过程。
- SQL 流式查询语言:
- 流式 SQL 查询语言的发展,如 Apache Flink 的SQL API 和 KSQL(Kafka Streams 的 SQL 接口),使得用户可以通过类 SQL 语法编写复杂的流式处理逻辑。
日志与时序数据属于典型的半结构化或者弱结构化数据,在此基础上微软推出了 KQL(Kusto Query Language)、 Splunk 推出了 Splunk Processing Language,他们都有如下特点:
- 直观的数据搜索和探索:
- 使用户能够通过简单的搜索语法直接查询数据,类似于如何在搜索引擎中查询信息。
- 强大的数据处理能力:
- 考虑到了需要在大数据集上执行复杂的数据处理和转换操作,例如统计计算、数据分组和排序。
- 灵活的数据分析:
- 提供了多种命令和函数,使用户可以灵活地分析数据,包括对时间序列数据进行可视化、识别模式和异常以及创建复杂的数据关联。
- 实时和历史数据处理:
- 能够处理实时数据流和历史数据存储,使得用户能够进行即时监控以及过去事件的分析。
- 可扩展性:
- 允许用户创建自定义搜索命令和脚本,从而扩展语法的功能,使其能够满足特定的业务需求。
- 易于学习和使用:
- 设计注重于易用性,意味着即使是非技术用户也能够通过简单的查询和命令来分析数据。
在此背景下,SLS 推出了 SPL(SLS Processing Language)语法,以此统一查询、端上处理、数据加工等的语法,保证了数据处理的灵活性。iLogtail 作为日志、时序数据采集器,在 2.0 版本中,全面支持了 SPL 。

2. SPL 和 iLogtail Pipeline 模式的对比
在支持 SPL 之前,iLogtail 在做数据解析的时候,使用的是 Pipeline 模式。
2.1 iLogtail 1.X Pipeline 模式
从整体来看,iLogtail 的文件采集模式可以划分为以下两种:
原生插件解析模式

如上图中间部分所示,纯 iLogtail 的核心处理部分由日志切分(Splitter)和日志解析(Parser)组成,均由 C++ 实现,根据选择的日志采集模式,日志切分把读取的文件内容切割成为一条条日志(比如单行基于换行符、多行基于行首正则),然后交由日志解析从单条日志中提取字段。仅能支持正则、Json 和分隔符模式等固定模式[1],且无法自由组合。这种基于采集模式的解析,拥有更好的性能,但牺牲了灵活性。
拓展插件 Pipeline 模式
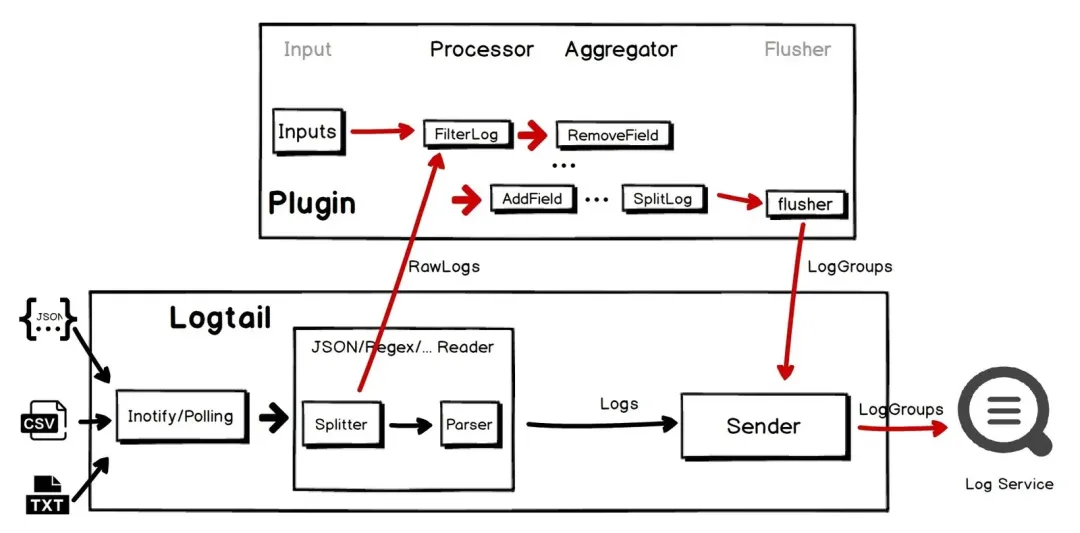
在拓展插件模式下,iLogtail 会将日志切分的结果直接提交给 Golang 插件模块进行处理,在后者中,我们可以组合多种处理插件[2],来满足我们的需求。拓展插件模式则是牺牲一定的性能和计算资源来换取灵活性,以应对更为复杂的场景。
iLogtail 1.X Pipeline 模式的局限
灵活性和性能只能二选一
- 原生插件模式性能最强,但是支持的格式有限。
- 拓展插件模式灵活性足够,但是资源消耗变大、性能有损耗。
- 引入 Golang 插件之后,C++ 到 Golang 插件跨语言传递数据,会引入额外的序列化与反序列化的步骤,带来一定的性能下降。
- Golang 相关解析函数的性能,还是要比 C++ 的低。
条件判断
iLogtail 插件的配置,还是更加适合格式比较固定格式日志的处理与解析。如果日志格式比较多样,单一的 Pipeline 是很难处理的,则需要配置多个 Pipeline。
配置简便性
iLogtail 控制台采集配置页面对每个插件都有对应的配置模块,想要做复杂的配置,页面上的交互还是会比较繁琐。
2.2 iLogtail2.0 + SPL
那么有没有一种方案,可以实现既要性能,又要灵活性呢?
ilLogtail2.0 带着 SPL 一起来了。iLogtail 2.0 中,SPL 是跟 Pipeline 并列的一个实现,底层调用了 SLS 统一的 SPL Lib,由此可以使用 SPL 完整的处理能力。
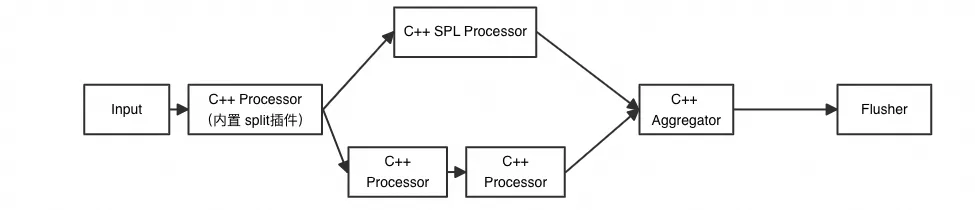
从 SLS 控制台可以看到 SPL 模式和 Pipeline 模式属于同级配置,两种模式可以选一种进行使用。

SPL 语法简介
语法结构
- 指令式语句,支持结构化数据和非结构化数据统一处理
- 管道符(|)引导的探索式语法,复杂逻辑编排简便
<data-source>| <spl-cmd> -option=<option> -option ... <expression>, ... as <output>, ...| <spl-cmd> ...| <spl-cmd> ...结构化数据 SQL 计算指令
- extend 通过 SQL 表达式计算结果产生新字段
- where 根据 SQL 表达式计算结果过滤数据条目
*| extend latency=cast(latency as BIGINT)| where status='200' AND latency>100字段操作指令
- project 保留与给定模式相匹配的字段、重命名指定字段
- project-away 移除与给定模式相匹配的字段,原样保留其他所有字段
- project-rename 重命名指定字段,并原样保留其他所有字段
*| project-away -wildcard "__tag__:*"| project-rename __source__=remote_addr非结构化数据提取指令
- parse-regexp 提取指定字段中的正则表达式分组匹配信息
- parse-json 提取指定字段中的第一层 JSON 信息
- parse-csv 提取指定字段中的 CSV 格式信息
*| project-csv -delim='^_^' content as time, body| project-regexp body, '(\S+)\s+(\w+)' as msg, useriLogtail2.0 + SPL 的优势

SPL 语法全局统一
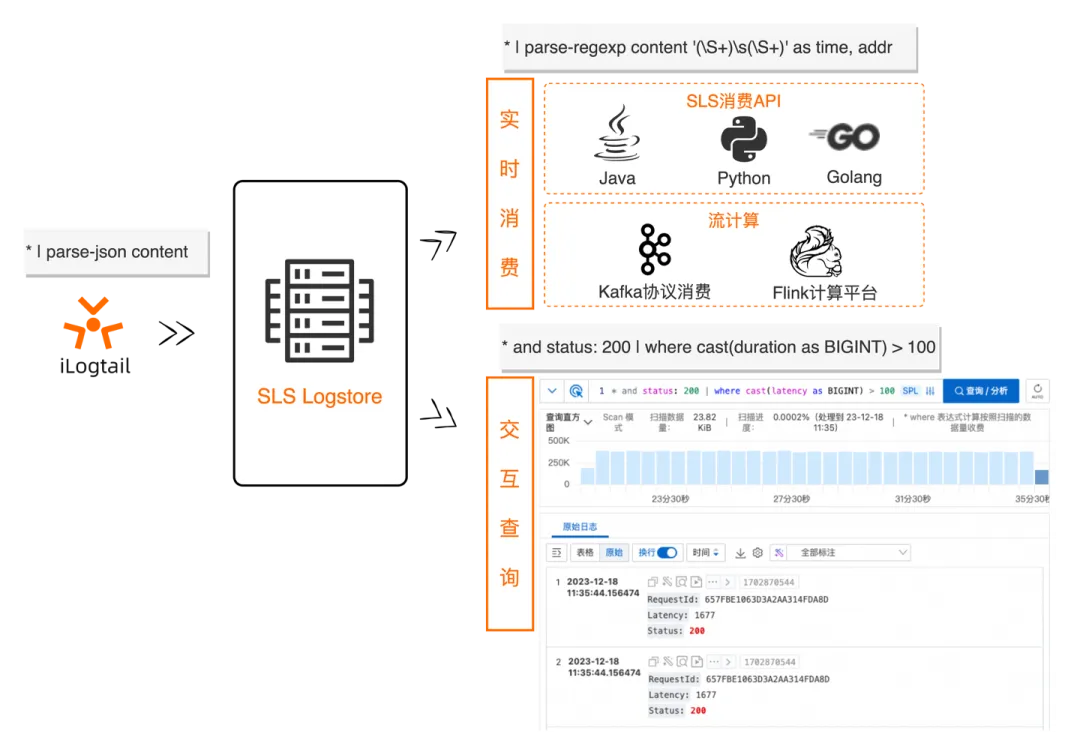
比如原来同样一个格式的数据,数据加工和 iLogtail 采集的配置是完全不同的,可能会导致客户需要有两个配置。现在 SPL 语法统一之后,同样的配置基本可以无缝在 iLogtail 和实时消费中转换。
C++ 原生高性能处理能力
SPL 的核心算子,都是 C++ 实现的,性能能够接近 iLogtail 原生 C++ 插件的性能,远高于 Logtail 拓展插件的性能。

丰富的函数支持
SPL 目前支持的函数已经全面对齐 SLS SQL 语法的函数。(SPL 支持的函数列表[3])
上手简单,调试方便
自动识别当前所处的语法模式,并对 SPL 相关指令和函数进行智能提示:


iLogtail 采集配置页面支持 SPL 预览,方便上手调试,可以实时看到配置效果:
3. iLogtail2.0+SPL 实战
下面我们通过一个实际的例子来体验一下。
3.1 SPL 配置入门
如下是一条混合了 json 和 java 堆栈信息的样例日志:
[2024-01-05T12:07:00.123456] {"message": "this is a msg", "level": "INFO", "garbage": "xxx"} java.lang.Exception: exception发生 at com.aliyun.sls.devops.logGenerator.type.RegexMultiLog.f3(RegexMultiLog.java:130) at com.aliyun.sls.devops.logGenerator.type.RegexMultiLog.f2(RegexMultiLog.java:125) at com.aliyun.sls.devops.logGenerator.type.RegexMultiLog.f1(RegexMultiLog.java:118) at com.aliyun.sls.devops.logGenerator.type.RegexMultiLog.run(RegexMultiLog.java:70) at java.base/java.lang.Thread.run(Thread.java:833)我们先来看下 iLogtail 插件模式是如何配置的:
- 开启多行模式,配置行首正则表达式
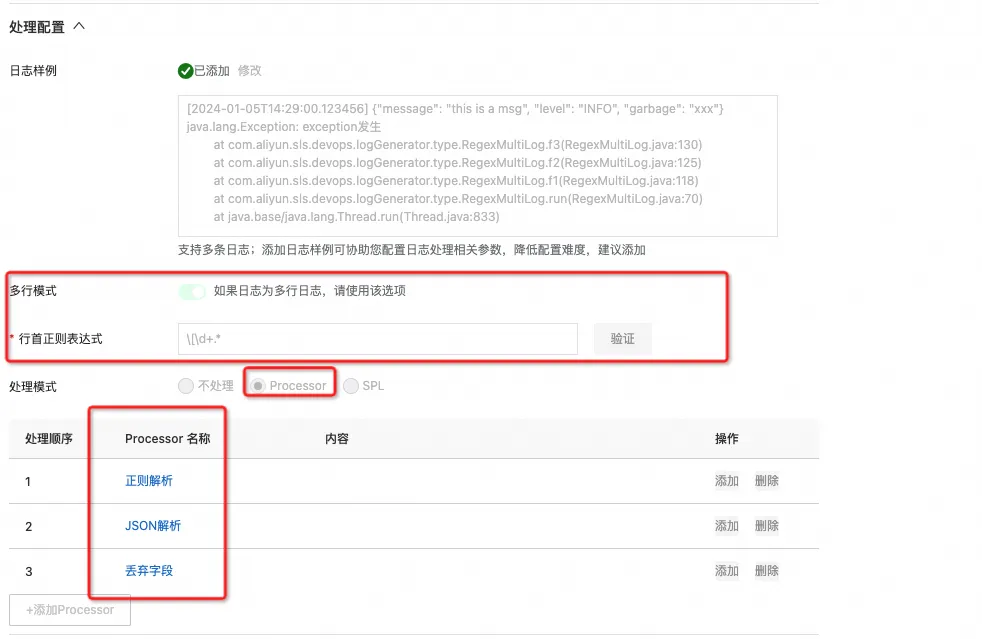
- 依次配置 Processor 插件
我们先用正则解析插件将原始日志分割成三个字段:time,json 和 stack:

然后配置 Json 解析插件,将 json 字段解析开:

最后配置丢弃字段插件,将不需要的字段丢弃:

然后我们再来看下 SPL 是如何配置的。
通过上面的步骤分析,我们发现这个解析过程拆解到 SPL 中可以使用如下配置。
第一步是正则解析,从原始字段中通过正则表达式,解析出 time, json 和 stack 三个字段:
parse-regexp content, '\[([^]]+)]\s+([^}]+})\s+(.*)' as time,json,stack第二步是 json 解析,从 json 字段中解析出 level,message 和 garbage 字段:
parse-json json第三步是丢弃字段:
project-away garbage,json这里需要注意的是,parse-json,parse-regexp 解析成功之后,是不丢弃原始的字段的,因此如果最后的数据中不需要原始字段,那么需要主动删除一下原始字段。
将上面的语句用管道符号连接起来,就得到了完整的 SPL 语句:
* | parse-regexp content, '\[([^]]+)]\s+([^}]+})\s+(.*)' as time,json,stack | parse-json json | project-away garbage,json,content最终配置如下图所示:
-
开启多行模式,配置行首正则表达式
-
处理模式选择 SPL,填入 SPL 语句

从控制台交互上看,SPL 配置的交互更加简便,不需要一个插件一个插件配置。
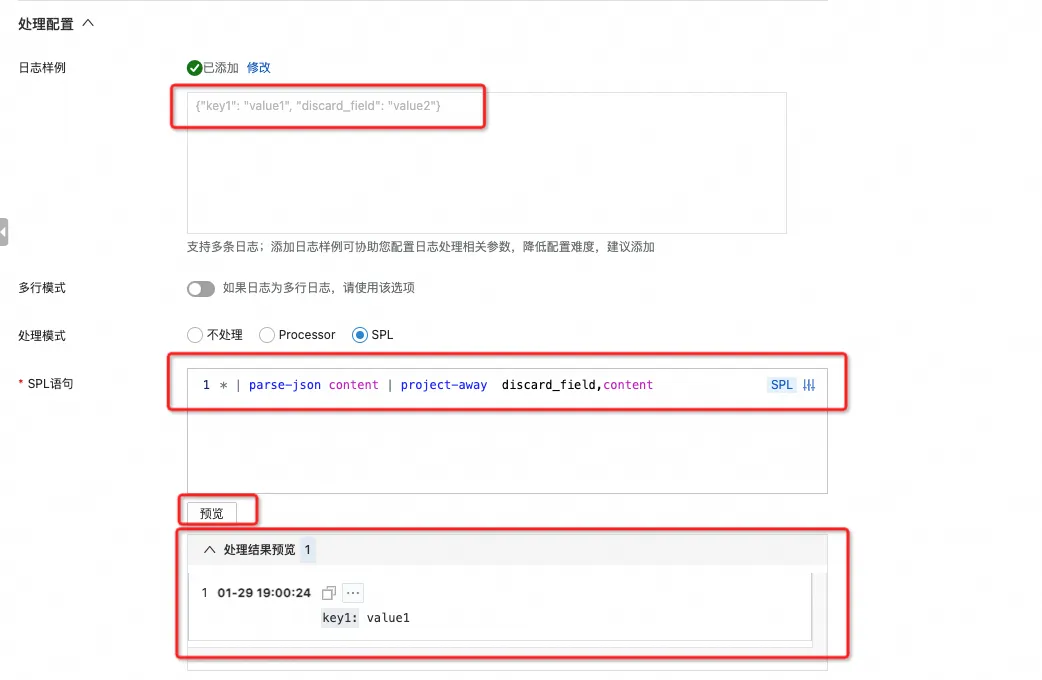
3.2 SPL 调试利器- SPL 配置效果预览
针对 SPL 的配置,控制台还提供了样例日志实时预览 SPL 处理结果的功能,添加日志样例之后,点击预览按钮,就是可以看到当前 SPL 语句的处理结果,可以非常方便的进行调试和优化。
继续用上面的例子,我们可以一步一步看到 SPL 配置的效果:
第一步是正则解析:
parse-regexp content, '\[([^]]+)]\s+([^}]+})\s+(.*)' as time,json,stack
可以看到数据被分割成了 time、json 和 stack 三个字段,原始字段 content 仍然保留着。
然后我们把 json 解析也加上,继续看下效果:
parse-regexp content, '\[([^]]+)]\s+([^}]+})\s+(.*)' as time,json,stack | parse-json json
可以看到 json 字段也被解析出来了,得到了 message,level 和 garbage 字段,同时 json 字段也被保留下来。到这里,所有字段解析都完成了,最后,我们就删除掉一些我们不需要的字段就好了。
* | parse-regexp content, '\[([^]]+)]\s+([^}]+})\s+(.*)' as time,json,stack | parse-json json | project-away garbage,json,content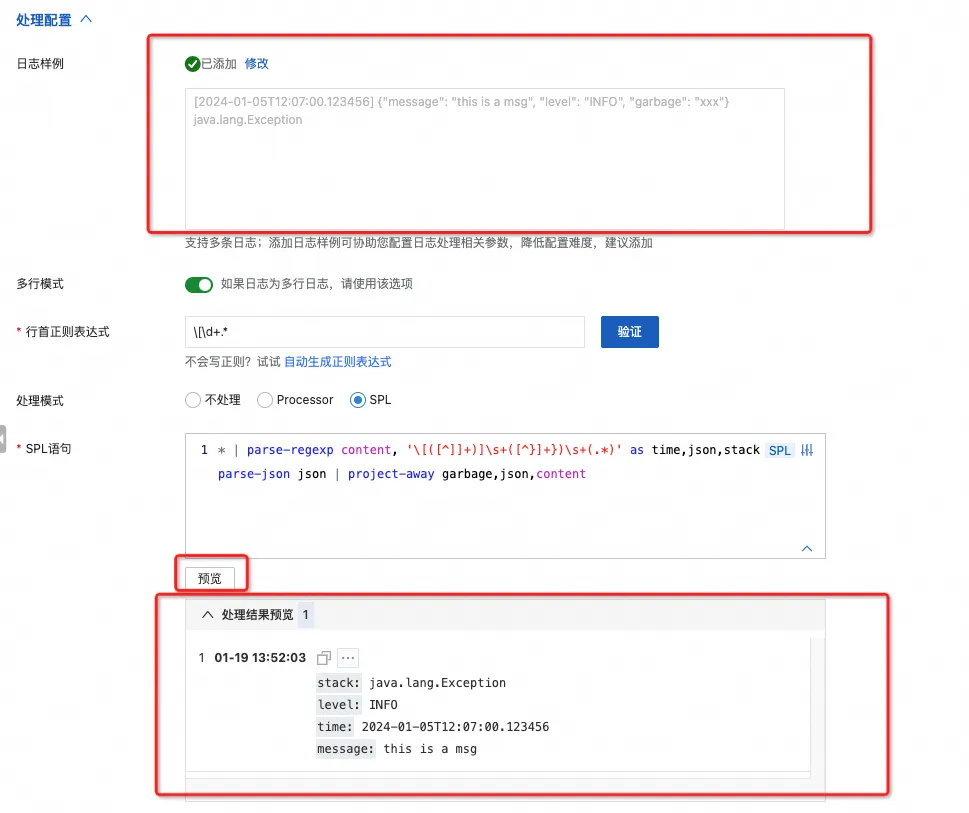
可以看到,garbage,json 和 content 字段都被删除了,整个过程非常轻松和高效。
3.3 开源 iLogtail 配置实践
开源的 iLogtail 配置 SPL 也是非常简单的,如下就是一个 SPL 配置的实例:
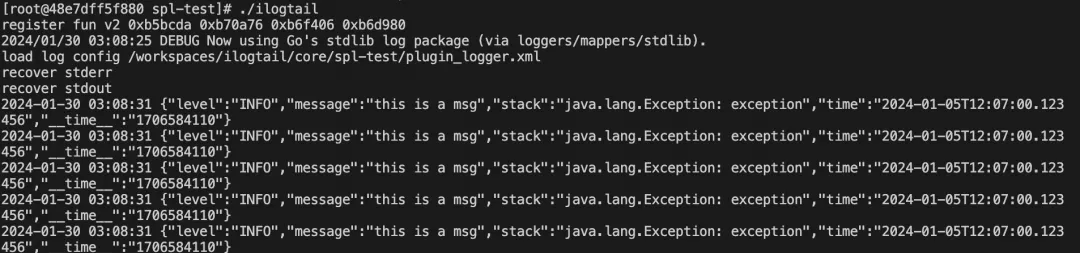
enable: trueinputs: - Type: input_file FilePaths: - /home/test-log/test.log Multiline: StartPattern: \[\d+.*processors: - Type: processor_spl Script: '* | parse-regexp content, ''\[([^]]+)]\s+([^}]+})\s+(.*)'' as time,json,stack | parse-json json | project-away garbage,json,content'flushers: - Type: flusher_stdout OnlyStdout: true模拟数据写入:

可以看到数据已经被正确的解析出来了:
4. 总结
日志数据格式可能是多样且复杂的,iLogtail 插件配置模式已经可以很好的支持复杂数据的处理。iLogtail2.0 又带来了 SPL 语法的重大支持,在日志处理场景下,可以通过多级管道对数据进行交互式、递进式的探索和处理,从配置交互和性能上,都有比较大的提升和优化。
iLogtail2.0 已经在逐步灰度中,欢迎大家体验和使用。
相关链接:
[1] 原生插件
[2] 扩展插件
[3] SPL 支持的函数列表