同一份日志,流量膨胀上万倍?!踩坑 Linux 文件系统
背景
本文的案例来自于一个真实的客户工单。大背景是客户从自建云将日志服务迁移到阿里云 SLS,其中使用 Logtail 来采集 K8s 环境中的日志。Logtail 作为一个非侵入式的日志采集器,读取业务应用写入到磁盘上的日志文件,并上传至 SLS。
客户在迁移过程中,分别试用了两种采集模式对同一份日志进行双写,但却发现了两种采集模式的流量出现了巨大差异。如下表所示,第一行为 Sidecar 模式采集,Logtail 版本 1.1.1,第二行为 Daemonset 模式采集,Logtail 版本为 1.8.6。
| 日期 | Logstore | 写入流量 (GB) | 索引流量 (GB) | 存储空间(GB) |
|---|---|---|---|---|
| 20250111 | 正常 | 0.61748 | 3.25344 | 27.00583 |
| 20250111 | 异常 | 59.2945 (+97 倍) | 11779.25 (+15399 倍) | 1149.806 |
异常 Logstore 的读写流量比正常的 Logstore 超出了近 100 倍,而索引流量则膨胀了上万倍!
问题排查
初窥门径
遇到流量差异如此巨大,第一反应就是出现了重复采集。所以,首先查看了一下原始日志,确认是否重复了。
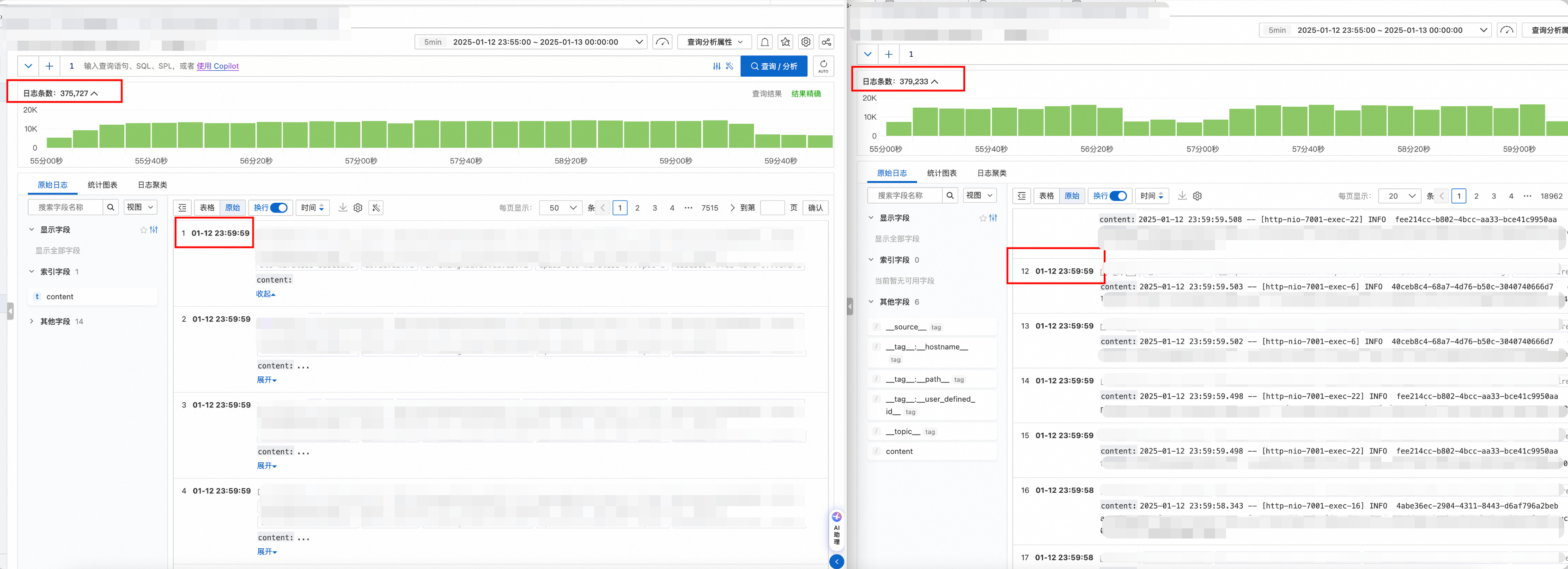
左侧为异常的 Logstore,右侧为正常的 Logstore。对比可以发现有两点异常的地方:
- 异常 Logstore 有很多日志超长截断的告警(Logtail 默认一条日志最大长度为 512KB,如果超出长度,那么则会截断并告警)。
- 从 Logtail 自监控查看流量,可以发现异常的 Logstore 对应的流量行为非常反常(该图中的具体数值还受其他 Logstore 影响,但可以大致反应出异常 Logstore 的情况。)采集行数激增的情况下,压缩后的采集流量却降低了很多。
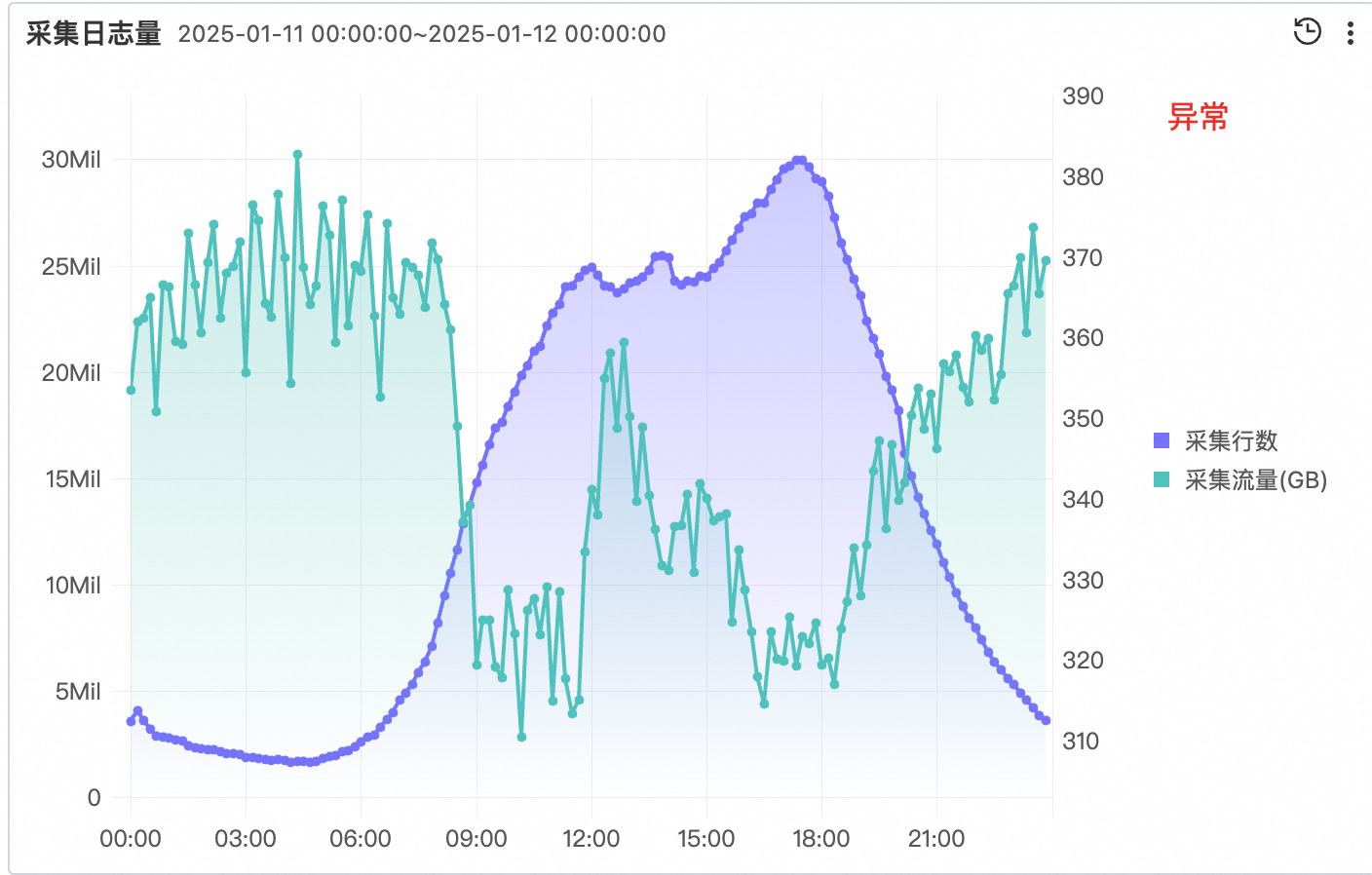
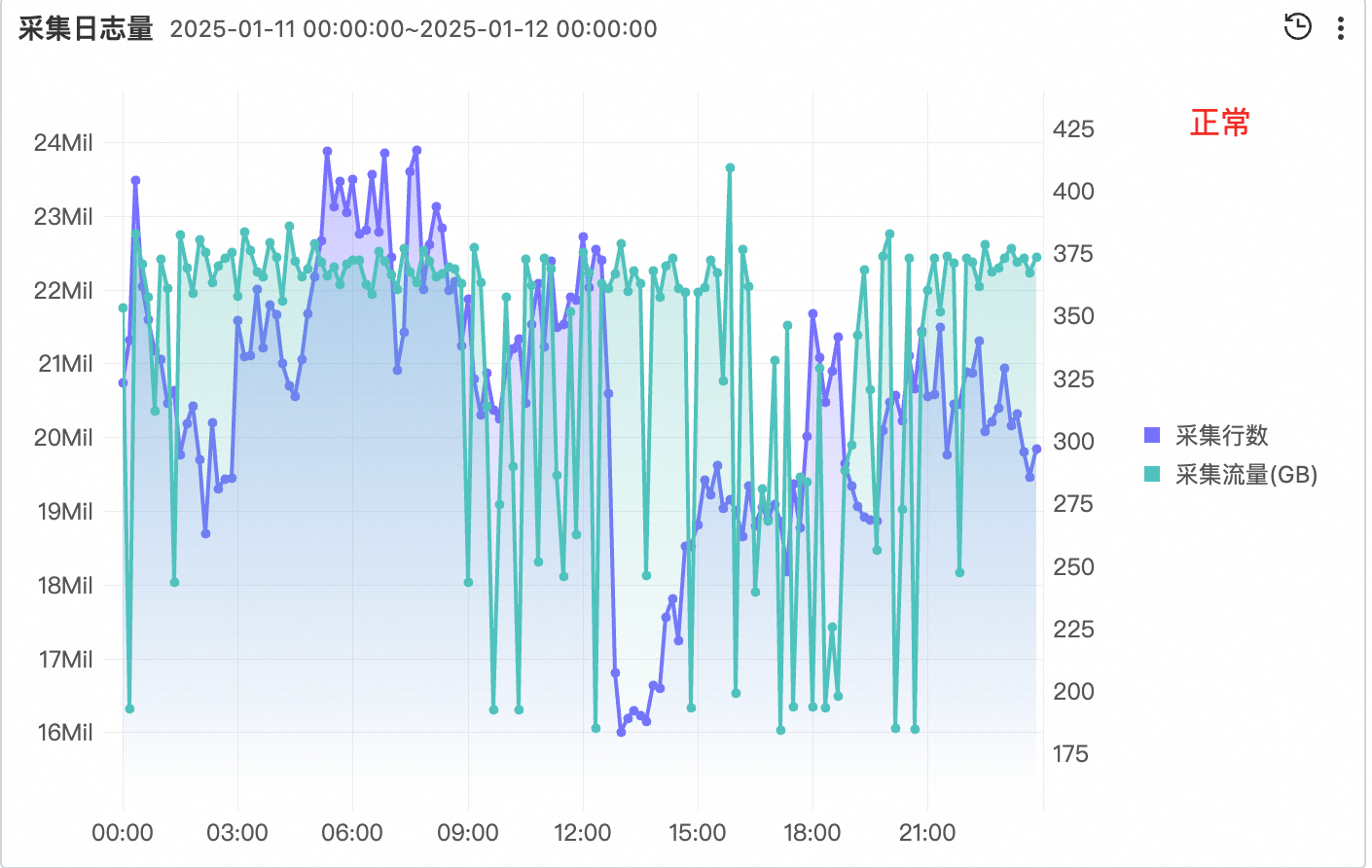
- 异常 Logstore 中有大量日志在控制台显示为空。将日志内容复制出来,发现是大量的 \0。
根据上面这三个现象,再结合 Logtail 两个版本之间的差异,我们可以初步确定问题的原因:
Logtail 在读取日志时,读到了大量的 \0。\0 在 C++ 中常被认为是一个字符串的结束,因此在 1.1.1 版本中,会丢弃这些 \0。但为了解决一些客户日志中存在正常 \0 的问题,Logtail 在后续版本中通过长度判断字符串是否结束,因此不再会忽略 \0。
异常 Logstore 采用了较新的 Logtail 版本,所以把 \0 都正常采集上来了。而正常 Logstore 中采用了较旧的 Logtail 版本,恰好碰巧忽略了 \0,实现了正常的采集。
这个原因也可以很好地解释之前观察的现象:
- 超长告警:Logtail 中以 \n 作为一行的结束。而客户日志文件中包含了大量的 \0,构成了超长的一行日志。因此触发了超长的截断,并将大量的 \0 聚合成一条日志发送。
- 采集流量:由于日志传输使用了 PB 数据结构和压缩算法,而异常日志中都是重复的 \0。因此会导致采集的压缩率特别高,反映到流量上,增加的没有那么显著。但解压后的读写流量,就成倍增加了。
- 索引膨胀:客户对于日志配置了索引,而日志中存在了大量的 \0,会导致建立索引时不断地进行分词,使得索引流量进一步膨胀。并且索引数据没有压缩,最终达到了上万倍这一恐怖的数值。
至于 Logtail 为什么读取到了这么多 \0,那么我们就需要进入到客户的集群中一探究竟了。
追本溯源
进入客户集群,我们查看日志文件的大小,就会发现问题所在。

可以看到,通过 ls 获取到的文件大小为 198GB,而通过 du 获取到的文件大小为 12MB。
首先,我们需要了解一下 ls 和 du 的区别。ls 是从文件系统的角度去看文件大小,获取的是文件元信息中文件长度这个字段。而 du 则是从磁盘的角度去看文件大小,获取的是文件实际占用的数据块的大小。一般来说,du 的结果都会比 ls 的要大,因为有些数据块是没有被完全填满的。而客户环境中 ls 的结果要远大于 du,属实异常。
与客户沟通发现,客户对于日志的轮转做了一些特殊操作。客户其实分为了两个组,一个是业务组,负责用日志框架把日志写入到文件中。另一个是运维组,负责维护他们集群。而业务组在打日志时,没有配置日志轮转,从而会导致旧日志始终累积在磁盘中,导致 node 节点存储压力过大。因此,运维组就想到一个办法,写了一个定时脚本,删除 java.logs 这个日志文件。
查阅相关资料后发现,客户这个操作看似合理,实际上却触发了 Linux 文件系统的一个特性,稀疏文件。
背后真凶——稀疏文件
网上有一篇相关的技术博客,对于稀疏文件进行了比较好的介绍,感兴趣的读者也可以阅读 https://www.tanglei.name/blog/difference-between-du-and-ls.html
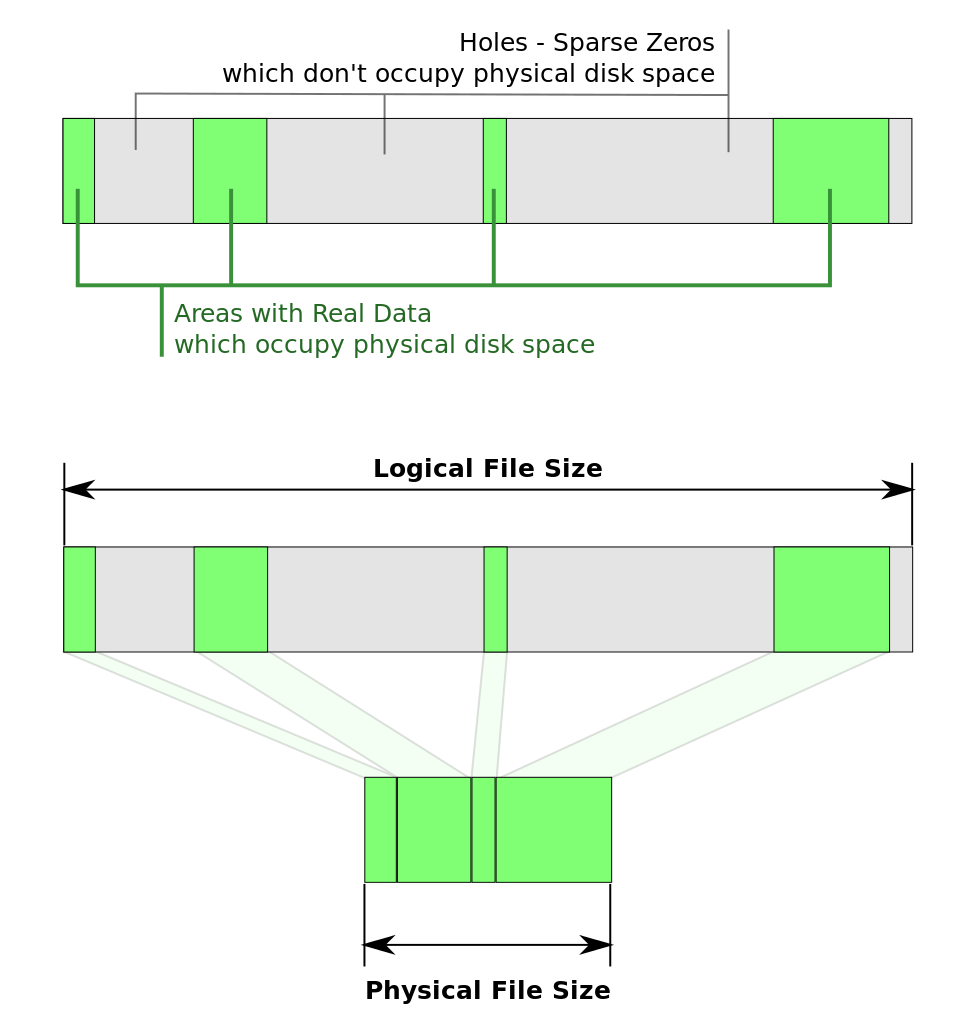
稀疏文件的本意是抽象出一个逻辑文件大小,而不是在磁盘上占用实际空间来存储空数据块。只有真实(非空)的数据块会按原样写入磁盘。稀疏文件的优势是,用户可以预先声明很大的存储空间,而这些空间只有在真实使用时才会被分配,节省了磁盘空间。当我们通过 ls 和 du 来查看一个稀疏文件大小时,就会出现之前说的那种 ls 远大于 du 的情况。
那么,稀疏文件是怎样创建出来的呢?除了显式地调用命令 <font style="color:rgb(32, 33, 34);">dd</font>来创建,还可以手动调整文件写入的指针位置。通过 <font style="color:rgb(32, 33, 34);">lseek(fd, 1024*1024*10, SEEK_END)</font>即可将写入指针向右移动 10MB,并且文件大小也会随之膨胀。
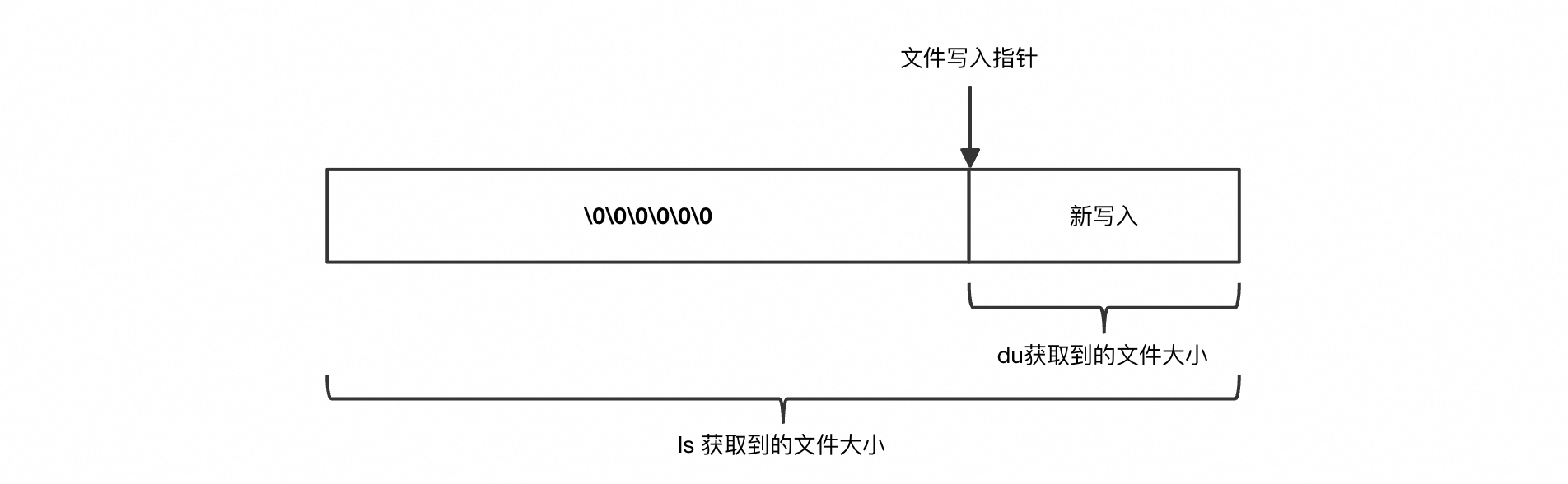
在这个客户场景中,由于业务应用始终持有日志文件的句柄不释放,所以采用了软删除来清理日志。定时脚本每小时 echo 一个空字符串覆盖日志文件,然而业务应用并不清楚文件已经被情况了,所以仍然采用了之前旧的写入指针偏移量,写入了新的日志。这就导致如上图所示,整个日志文件中,开头存在大量的 \0,形成了稀疏文件。
对于 Logtail 来说,由于文件开头的内容发生了变化,导致 Logtail 对文件的签名也发现了变化,从而认为是一个新的文件,从头开始新的日志文件,并且通过系统调用,获取文件的大小。这与 ls 的结果是相同的,因此获得了一个累积的值(例如前文中提到的 198GB)。根据这个文件大小,Logtail 开始不断移动文件读取指针,最终读取了大量的\0。
启发
这个案例虽然是客户的错误操作导致的日志膨胀,但对于我们平时轮转日志和采集日志来说,都有着一些借鉴意义。
如何正确地轮转日志
对于日志的生成者,各种业务应用来说,最规范的输出日志方法,还是从业务侧就实现日志轮转机制。避免在外部实现日志轮转,减少并发操作同一个文件,导致稀疏文件或者其他意料之外的情况。
常见的日志轮转方式有两种:
- Rename:通过将当前日志文件重命名为一个新的文件名,然后让应用程序重新创建一个新的日志文件来实现轮转。
- 优点:因为是通过重命名实现,原始日志文件在轮转后不再被写入,避免了数据丢失。
- 缺点:在重命名和创建新日志文件的过程中,可能会有短暂的日志写入中断。
- Copytruncate:通过复制当前日志文件的内容到一个新的文件中,然后截断原始日志文件,使其清空以继续写入新日志。
- 优点:由于文件描述符未变,应用程序可以无感知地继续写入日志,不会有写入中断。
- 缺点:在复制和截断之间,可能会有少量日志数据未被复制或被重复写入。对于大型日志文件,复制操作可能会产生较高的磁盘 I/O 开销,影响系统性能。
而日志轮转的规则,开发者可以根据自己的需求,选择根据文件大小、文件时间、文件个数等限制,来控制日志文件所占用的磁盘空间。
如何正确地采集日志
正常情况下,日志文件没有利用任何稀疏文件的特性,不应当是一个稀疏文件。但对于这类特殊情况,Logtail 等日志采集器未来可以通过判断文件大小与实际占用的数据块大小,从而区分出稀疏文件,进一步忽略其中的 hole。