从 o11y 2.0 说起,大数据 Pipeline 的「多快好省」之道
什么是 o11y 2.0
o11y 2.0(可观测性 2.0)是最近半年 DevOps 领域的热点话题,HoneyComb 介绍了《Introducing Observability 2.0》【1】, CNCF 则引述了 Middleware 定义的《What is observability 2.0?》【2】。
对于 o11y 2.0 要解决什么问题,如下是笔者的一些理解:
- 打破 Log/Metric/Trace 各自为战的局限性,在一个统一平台下,建立针对系统健康度的完整视图。
- 核心是让工程师更快地理解系统行为、诊断问题,减少停机时间,包括将 AI 技术应用到异常识别、故障定位等场景。
- 以日志数据为核心,通过增加信息维度、补全上下文信息(Wide Events),让日志还原事实。
- 用云原生架构提供弹性伸缩、易于使用、低成本的系统,在海量事件数据上进行查询和分析,从而去发现、解决问题。
可观测 2.0 提倡以事件为核心的宽键值对、结构化事件模型,支持多维度、高粒度的数据表示,使系统状态、行为能够被精确描述和查询。因此,在可观测系统选型时应重点考察:
- 存储系统:应对海量、格式多样的实时数据流,提供低延迟、高写入吞吐能力;同时要支持高维、结构化数据的存储与查询加速能力。
- 计算系统:在即时分析上秒级进行十亿级数据统计;支持弹性扩展的实时计算能力,能够动态关联多源数据、维度表,完成复杂事件的数据加工。
数据 Pipeline 是计算系统中的重要组件,其定位是加工出高质量的 Wide Events。就像是炼化厂从原油中炼制出燃料、沥青、液化石油气。
SLS 是阿里云可观测家族的核心产品之一,提供全托管的可观测数据服务。本文以 o11y 2.0 为引子,整理了可观测数据 Pipeline 的演进和一些思考。
可观测数据 Pipeline 的演进
SLS 在 2019 年推出数据加工功能,我们从 2024 年开始推进数据 Pipeline 换代升级。演进升级为企业用户带来了什么变化呢?笔者借用“多、快、好、省”四个字作为概括,也是期许。
形态更多
SLS 升级后的数据 Pipeline 服务,提供三种形态:

真的需要这么多形态吗?从当前发展阶段来看,这三种形态存在的确都有来自场景能适用性、容错能力、成本费用、生态集成方面的合理需求,分别肩负着解决各自场景问题的使命。
| 功能 | 写入处理器 | 消费处理器 | 数据加工 |
|---|---|---|---|
| 使用形态 | 用户维护写入客户端,SLS 收到数据做计算、落库后响应客户端 | 用户维护消费客户端,SLS 收到请求后读数据做计算后响应客户端 | SLS 全托管服务,流式读取源库数据,计算后写入目标库 |
| SPL 算子支持 | 部分能力 适合简单的过滤、预处理场景 | 部分能力 适合简单的过滤、预处理场景 | 完整能力 包括:复杂计算、Lookup、多目标分发等能力 |
| 计算容错性 | 中 1. 处理失败时可上传原文字段 2. 复杂计算可能增加客户端写入请求耗时(百 ms 级) | 高 1. 基于持久化的数据,可重复消费计算 2. 复杂计算可能增加客户端读取请求耗时(百 ms 级) | 高 1. 基于持久化的数据,可重复消费计算 2. 支持负载均衡、分片发现,自动进行异常重试 |
| 数据场景可扩展性 | 数据使用场景较固定 | 数据按原文写入,在多种消费场景下可以分别做个性化处理 | |
| 计算费用 | 相同 | ||
| 存储费用 | 存:计算后结果数据 | 存:原文数据、计算后结果数据 存储一天原文数据的费用约等于流一遍数据计算的费用 |
数据加工是全托管服务,本次进行了架构升级。写入、消费处理器则是全新推出的功能,为上下游生产者、消费者提供了更多选择。
以消费处理器为例,Flink 是最重要的生态系统之一,在数据过滤下推、跨区域数据拉取计算场景中,获得了多个大数据规模的客户采纳。

性能更快
性能对于日志 ETL 是最重要的事情呢?是。一方面因为实时性,在可观测场景下,从秒到小时级新鲜度,数据价值差别很大;无论是传统的告警、异常日志搜索,还是基于故障根因分析、时序预测,都离不开实时的数据;基于流数据的 Pipeline 是数据 ms 级实时度的前提条件。另一方面是因为日志 ETL 干的活儿非常复杂,分析人员把 60% 时间花在准备高质量数据上,要做字段抽取、异常数据过滤、数据归一化、维表数据富化等等;可观测 2.0 倡导的 Wide Events 也对 ETL 性能间接提出要求,包括要关联更多的上下文信息,处理更大的 Event;因此,日志 ETL 需要更强的性能来实现在更多的数据上做更复杂的计算。
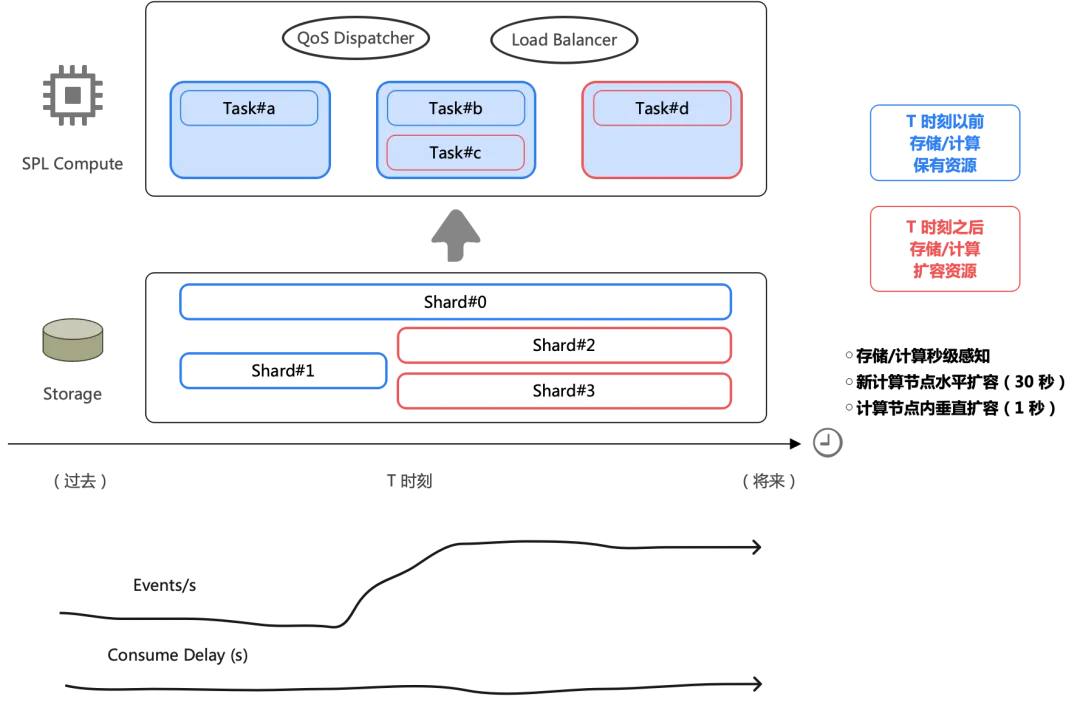
SLS 在日志 Pipeline 上以 SPL 引擎作为内核,包括列式计算、SIMD 加速、C++ 语言实现这些优势。基于 SPL 引擎进行分布式架构,我们重新设计了弹性的机制,不只是通常意义上按实例(K8s Pod 或是服务 CU)粒度的伸缩,可以按照 DataBlock 粒度(MB 级别)快速弹性。
如下图是一个真实日志场景,每天凌晨 0 点有一次日志写入脉冲,几秒内增加 2 倍。旧版数据加工在这种 burst 场景下表现不好,高峰出现两分钟延迟;新版加工在单位 CPU 吞吐能力上比旧版有大幅优化,加工消费数据的速率与日志产生的速率保持同频升高,延迟控制在 1 秒内。
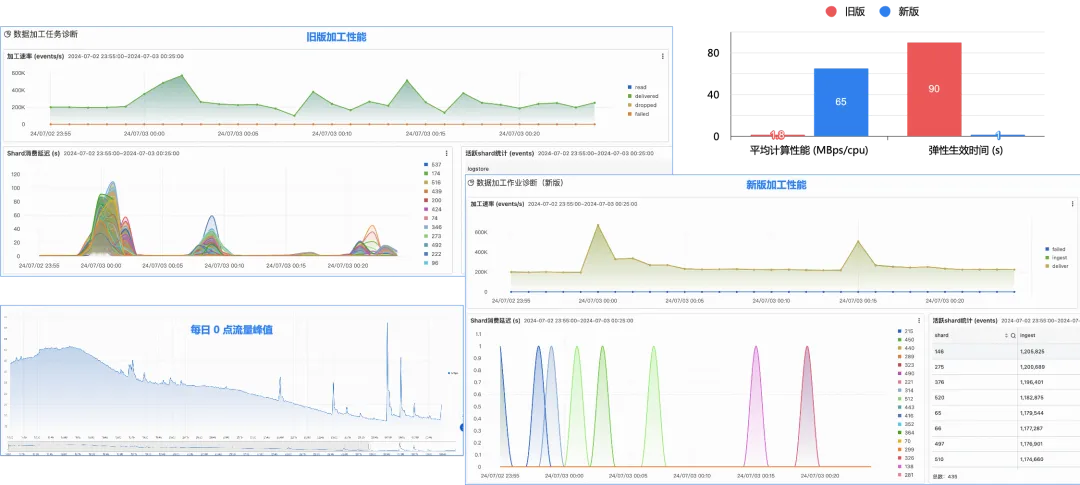
通过水平扩展,在简单过滤场景下,新版加工目前服务的最大单作业流量达到 1 PB/day(原文大小)。
体验更好
体验好坏是偏主观的事情。SLS 重点围绕 SPL 做了两项努力:
- 降低学习语言的成本:SPL 语法在表达式这一层完全复用了 SLS SQL 提供的几百个函数,能力上比旧版 Python-DSL 更完整了,同时对于 SQL 熟手来说减少了查手册的频次。SQL 体系要求数据 Schema 确定,这在日志场景下不够灵活,SPL 则扩展了一些 Schema-Free 指令(例如 parse-json 将不确定个数的子字段展开到第一层)。
- 渐进式地写低代码:SPL 的灵感估计是来自大家熟悉 Linux 命令(grep/awk/sort 等)与管道组合,过去在可观测厂商中有很多应用(Splunk、Azure Monitor、Grafana 等),今年 Google 在 SQL 上扩展了 Pipe Syntax In SQL,有个别厂商开始在通用分析领域跟进。

SLS 在 2023 年中开始推出 SPL,如下是查询场景下,渐进式写代码探索过程的最新演示:
值得一提的是,SPL 除了被用在即时查询、分析场景之外,无论是写入处理器、消费处理器、新版数据加工,甚至 Logtail 在端上都可以使用 SPL 编程。
比如,一份 SPL 数据预处理的语句在 Logtail 上工作良好,但需要更高的水平扩展能力,并且不希望占用业务所在机器节点的资源,您可以选择把 SPL 语句复制到新版数据加工上,保存下来就能实现相同效果的全托管数据处理。
成本更省
数据加工定价下调 66.7%
在 SPL 引擎相对旧版 Python-DSL 引擎做到显著性能提升后,SLS 将新版加工的定价下调到旧版的 1/3。
从 TCO 角度来看,节省下来的不只是计算费用。一个大型企业建设数据 Pipeline 有另外两处成本:
- 存储的分片费用:存储分片占用物理存储,往往会收取预留费用(或是影响自建软件服务上限),在计算性能不足的情况下一般通过增加分片数量(增加计算并发)或者优化加工逻辑来提升性能,增加分片是大部分时候的处理方案。
- 资源管理成本:日志库的分片扩容引入应急运维成本,在业务峰谷差异两倍以上时大量的库上做分片扩容操作容易手忙脚乱;同时,如果遇到非常复杂的 ETL 逻辑(单作业几十行以上),在性能不足时可能会分拆一些逻辑到新作业上,这又增加了一些对日志库、作业的管理难度。
三方软件、服务集成效率提升
SLS 提供了对多种软件(Flink/Spark/Flume 等)、服务(Dataworks/OSS/MC 等)的消费集成支持,而在个性化业务需求下则需要写代码,这个开发过程往往会遇到较多重复代码逻辑,并且新开发的代码做到高效、准确都需要投入较多时间和人力来保证。
这里举一个 SLS 和 FC 集成的例子,需求是在函数计算上编写一个程序:从 SLS 读取数据,过滤出错误信息(千分之二比例),对错误日志抽取出结构化的字段,将结果数据插入到数据库。
默认的做法是全量消费,在 Python 代码中完成全部 IO、计算过程(如下蓝图)。
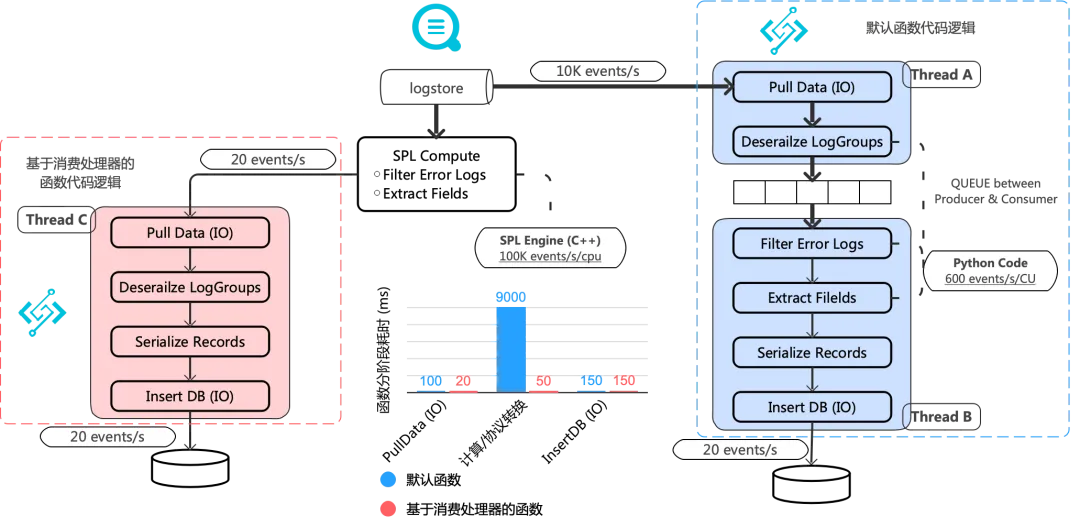
通过 SLS 消费处理器来做同样的事(如上红图),则会简单很多:
- 过滤、字段抽取是常用逻辑,通过 SPL 低代码的方式下推到 SLS 侧完成,大大节省了 Python 代码开发、测试的时间。
- 过滤、字段抽取往往是 CPU 密集型操作,SPL 计算相比快速改出来的 Python 代码有巨大的性能优势。
在一个高过滤比的客户场景下,处理 10MB 数据,端到端函数耗时从 10~15s 降低到 300ms。业务解决了消费延迟问题,同时,在函数按请求计费模式下,执行耗时下降也让函数的费用回归到合理。
跨地域带宽成本优化
相比较于计算的费用,Pipeline 引入的网络(公网、专线)费用才是大头。一般在三种场景下会遇到:
- 在阿里云多个 Region 部署业务,需要跨地域访问数据
- 混合云架构,部分云上数据需要传输到线下 IDC
- 多云架构

网络成本这么高,如何优化呢?第一步可以在链路传输上开启数据压缩,用最最节省空间的压缩算法(比如 ZSTD 在数据大小与 CPU 开销上做到很好的平衡)。再进一步,可以尝试从业务上做一些优化。
日志是二维结构,包括:行(每一条日志)、列(单条日志的某一个字段),在跨区域时只传输必要的数据,那么,流量费用就能做到合理。以下两种场景推荐通过 SLS 消费处理器做优化:
- 列投影:
* | project time_local, request_uri, status, user_agent, client_ip - 行过滤:
* | where status != '200'
结语
其实不止于可观测 2.0,AI 浪潮也正在带来大模型工具在生产落地,而可观测大数据存储、计算是它们的基石。我们相信基于 SPL 的可观测 Pipeline 在 Schema-Free 数据处理、Wide Events 加工、实时高性能、灵活可扩展上具有很强的优势。同时,我们正在持续增强 SPL Pipeline 的能力,敬请关注。