5% 消耗,6 倍性能:揭秘新一代 iLogtail SPL 日志处理引擎与 Logstash 的 PK
1. 引言
在当今数据驱动的时代,日志收集和处理工具对于保障系统稳定性和优化运维效率至关重要。随着企业数据量的不断增加和系统架构的日益复杂,传统日志处理工具面临着性能、灵活性和易用性等多方面的挑战。Logstash 作为一款广受欢迎的开源日志收集与处理工具,早已广泛应用于各类 IT 环境。然而,随着需求的多样化和技术的发展,新一代日志处理解决方案——iLogtail[1]应运而生。
近期,iLogtail 2.0 隆重推出了新功能 SPL 处理模式,进一步增强了日志处理的能力。在本文中,我们将深入探讨为何选择 iLogtail,以及它在 SPL 数据处理方面相较于 Logstash 有何独特优势。通过对比这两款工具的架构、性能以及功能,我们希望能够揭示 iLogtail 如何在日益复杂的日志处理需求中脱颖而出,帮助您做出明智的技术选择。
2. iLogtail & SPL 介绍
iLogtail 是阿里巴巴开源的日志采集工具,设计之初便针对大规模数据以及云原生场景进行了优化,旨在提供低延迟、高效率的日志收集解决方案。iLogtail 拥有轻量级、高性能、自动化配置等诸多生产级别特性,在阿里巴巴以及外部数万家阿里云客户内部广泛应用。你可以将它部署于物理机,虚拟机,Kubernetes 等多种环境中来采集可观测数据,例如 logs、traces 和 metrics。
iLogtail 2.0 版本新增了 SPL 处理模式。SPL 是一种专为日志这类非结构化数据设计的流式处理语言。SPL 的设计受到了 Unix 管道的启发。在 iLogtail 中,一条日志数据从数据源被采集上来后,会经过一系列处理操作,就像管道一样,最终流向下游的存储。因此,可以说 SPL 的设计天然适配了日志处理的场景。

除了语言本身所提供的灵活处理功能之外,iLogtail SPL 本身使用了大量的高性能技术。通过 SIMD 等并行化计算,在保持灵活性的同时兼顾了高性能。
3. iLogtail SPL vs Logstash Filter
Logstash 的 filter 插件提供了对日志数据的过滤、解析和修改能力。常见的插件如 grok(grok 正则解析)、date(时间解析)、mutate(修改字段)等等。通过将这些插件组合成一条流水线的方式,Logstash 提供了强大的日志数据处理能力。那么,与 iLogtail 的 SPL 处理模式相比,两者孰强孰弱呢?接下来,我们将从功能支持和场景性能两个方面进行 PK。
3.1 功能支持
根据最新的官方文档[2],Logstash 目前提供了 49 种 filter 插件功能,基本覆盖了常见的日志处理场景。用户通过在配置文件中编写配置,将这些插件组合起来。
SPL 作为一个流式处理语言,同样提供了丰富的算子和可编程性。根据最新的官方文档[3],SPL 提供了 8 种数据处理的指令,包括正则解析、Json 解析等等常见的功能。除此之外,SPL 还兼容大部分 SQL 指令,提供了 **110 **个 SQL 中常见的数据解析和处理指令,并且仍在积极开发,提供更多的处理功能。基于这些指令,用户可以编写 SPL 语句满足各种数据处理需求。
功能是否完整只是解决了有没有的问题,能否让用户轻松上手,用得爽还需要解决易用性的问题。接下来,我们列举一些常见的日志处理场景,对比一下两者配置的方式。
正则解析 + 时间解析
以 nginx access log 为例,输入:
142.207.88.67 - - [18/Jun/2024:12:14:26 +0800] "DELETE http://www.districtdot-com.biz/syndicate HTTP/1.1" 289 3715 "http://www.chiefscalable.biz/webservices" "Mozilla/5.0 (iPhone; CPU iPhone OS 8_2_1 like Mac OS X; en-US) AppleWebKit/534.46.7 (KHTML, like Gecko) Version/5.0.5 Mobile/8B119 Safari/6534.46.7"
Logstash 不支持原生正则,仅支持 Grok 这一正则拓展。作为比较基础的功能,Logstash 和 iLogtail SPL 两者使用体验相比差别不大。
不同条件下添加、删除、过滤字段
以一段简单的 Json 日志为例,根据其中的 user-agent 添加一个新的字段:
{"url": "POST /PutData HTTP/1.1", "user-agent": "aliyun-sdk-java"}
在 Logstash 中,由于配置文件本身有自身的一套语法,也提供了一定的可编程性。但作为配置文件语言,并不是特别擅长进行数据处理。其语法与 SPL 兼容 SQL 的语法相比,书写复杂度显然更高,使得配置文件冗长且难以管理。而且 Logstash 处理插件本身使用了 Ruby 实现,其对于数据并行性的利用也存在着一定局限性,在下一章中将进行详细地展开。
多层嵌套 Json 提取与解析
在很多情况下,原始日志是一个复杂的嵌套 Json 结构。对于其中的字段需要进一步处理才可以存入到后端中。假设如我们需要对以下的 Nginx 日志进行处理:
2024-06-24 12:26:04.063 INFO 24 --- [traceId=edda5daxxxxxxxxxcfa3387d48][ xnio-1 task-1] c.g.c.gateway.filter.AutoTestFilter : {"traceId":"edda5da8xxxxxxxxxxxxxxxxxxx387d48","headers":[{"x-forwarded-proto":"http,http","x-tenant-id":"123","x-ca-key":"a62d5xxxxxxxxxxxxxxxxxxxxxxxxb1cff8637","x-forwarded-port":"80,80","x-forwarded-for":"10.244.2.0","x-ca-client-ip":"10.244.2.0","x-product-code":"xxxxx","authorization":"bearer 0ed29xxxxxxxxxxxxxxxxxxxxxxxxx71899","x-forwarded-host":"gatxxxxxxxxx.gm","x-forwarded-prefix":"/xxxxxx","trace-id":"edda5da8278xxxxxxxxxxxxxxxxxxx49cfa3387d48","x-ca-api-id":"1418470181321347075","x-ca-env-code":"TEST"}],"appName":"超级管理员","responseTime":15,"serverName":"test-server","appkey":"a62d54b6bxxxxxxxxxxxxxxxxxxx37","time":"2021-08-01 12:26:04.062","responseStatus":200,"url":"/test/v4/orgs/123/list-children","token":"bearer 0ed29c72-0d68-4e13-a3f3-c77e2d971899"}包括以下的处理步骤:
-
提取 message 字段,得到 Json 格式的请求 body
-
对 body 进行 Json 解析
-
header 中仅有一个对象,将其字段平铺到最外层
-
分隔 x-forwarded-port 得到第一个端口
-
将 x-forwarded-host 和第一个端口以:拼接成一个新的字段,再拼接上 x-forwarded-prefix
-
删除其余不必要的字段
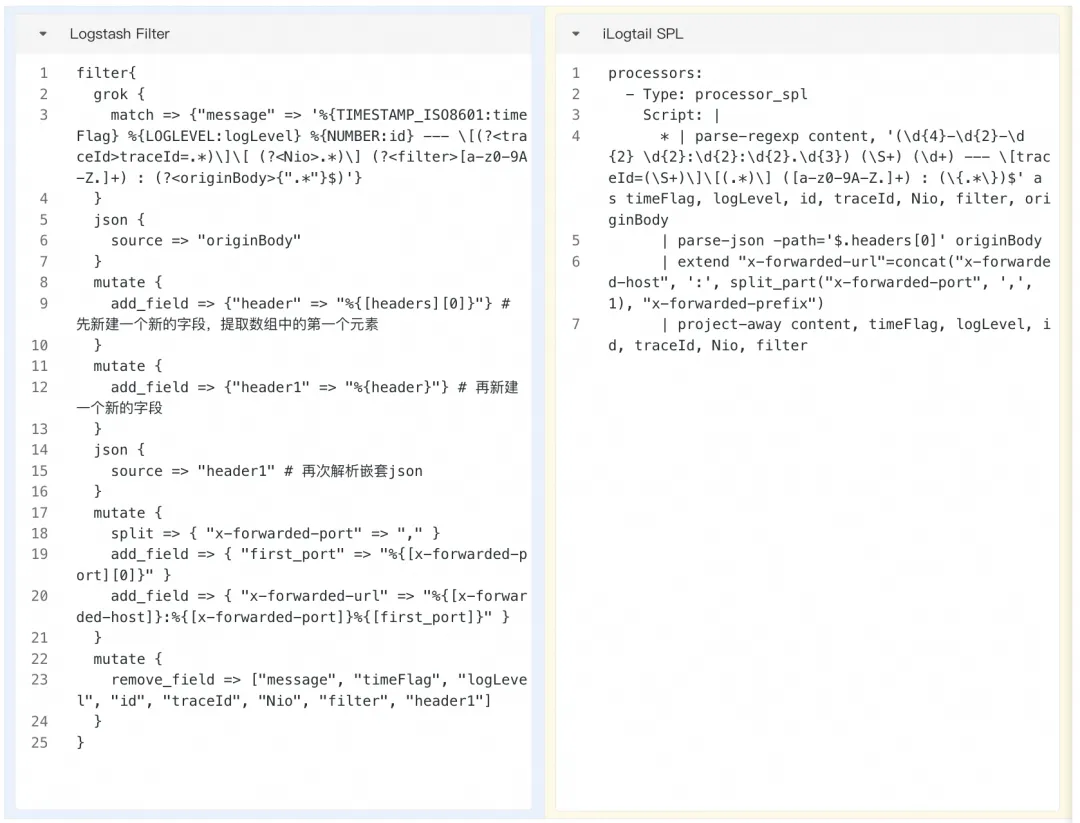
Logstash 不支持解析嵌套的 Json 日志,所以在解析时需要一系列麻烦的操作。iLogtail SPL 支持 JsonPath 解析,从而可以更简洁地从 Json 字符串中提取嵌套的字段的值。除此之外,与 Logstash 类似,iLogtail SPL 也提供了丰富的字符串操作方法,能够对字符串进行一系列复杂的解析操作。
3.2 场景性能
作为一个日志采集器,所占用的资源也至关重要。如果占用的资源过多,对用户的业务产生了影响,这也是不可接受的。接下来,本文将对 iLogtail 和 Logstash 采集日志时所占用的资源使用量进行对比。
由于 Logstash 本身不支持采集 K8s 场景下的日志,所以以 Linux 主机为测试场景,测试两个采集器在采集前文提到的 Nginx access log 时的资源占用情况。
- 测试环境:8 核 16GB,操作系统 Ubuntu 22.04
- 测试版本:iLogtail 2.0.4,Logstash 8.14.1,两者均使用默认参数配置
- 测试场景:
- 场景一:正则解析+时间解析
- 场景二:不同条件下添加、删除、过滤字段
- 场景三:多层嵌套 Json 提取与解析
- 测试数据:以 1MB/s、5MB/s、10MB/s 生成日志写入到文件中,总时长 3 分钟
为了避免数据下游导致的采集表现差异,iLogtail 和 Logstash 都通过过滤插件,将日志经过上述配置文件后,全部丢弃。通过这种方法,仅测试对比两者采集和处理的资源占用情况。
下面为三个场景中对 iLogtail 和 Logstash 进程资源使用量的监控:
场景一:正则解析+时间解析
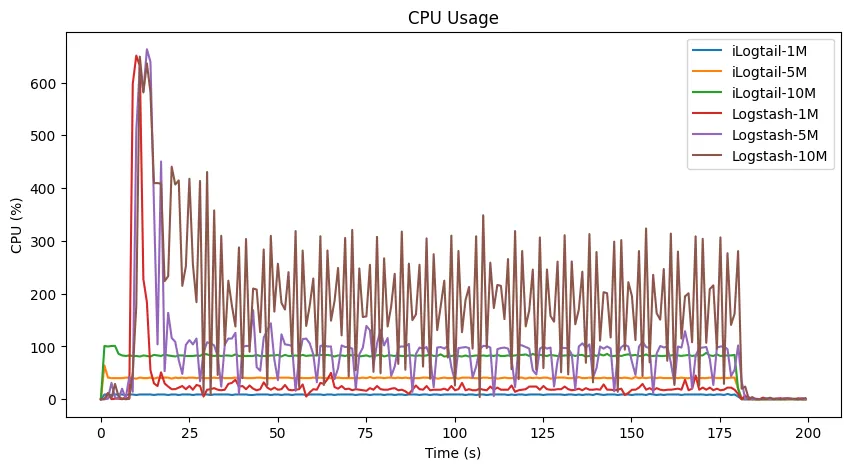

**观察:**在采集的一开始,Logstash 的启动延迟要明显比 iLogtail 高。同时,Logstash 的 CPU 使用率和内存使用率也远高于 iLogtail。Logstash 处理 1MB/s 所使用的 CPU 资源与 iLogtail 处理 10MB/s 的近似。除此之外,Logstash 的 CPU 使用率波动也明显更大。
场景二:不同条件下添加、删除、过滤字段
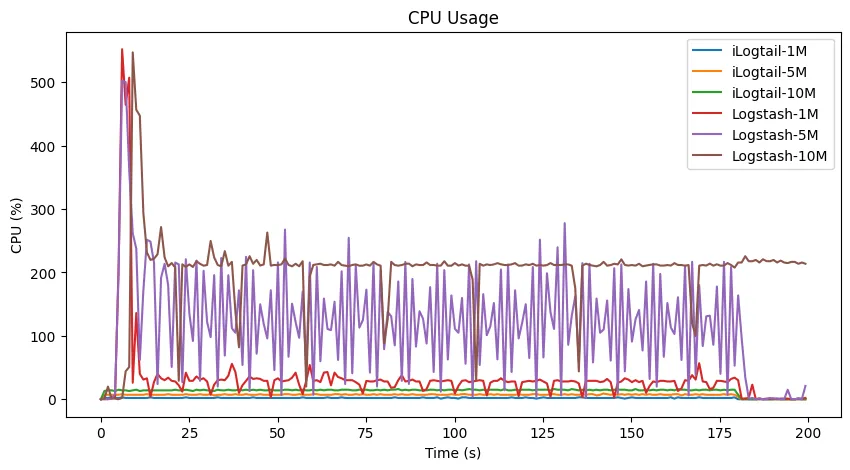
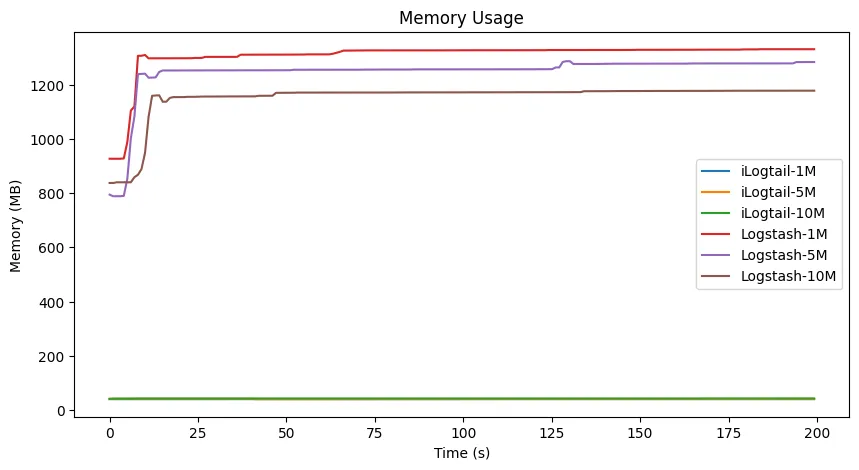
**观察:**在日志生成(180 秒)结束后,Logstash 仍然还在进行处理日志,说明其处理能力已经达到了瓶颈,采集出现了比较大的延迟。
为了进一步探究 Logstash 和 iLogtail 的采集瓶颈在哪里,我们进一步细化测试不同的日志生成速率,并以 CPU 使用率低于 0.1 作为采集处理结束,3 秒作为正常的采集延迟。最终,我们测试发现 Logstash 在场景二中的处理瓶颈在日志生成 8MB/s。而 iLogtail 在 50MB/s 仍然可以几乎无延迟地采集日志,并且资源使用仍然保持了较低的水平(CPU 使用率 130%,内存使用 61MB)。两者之间性能相差 6 倍!
场景三:多层嵌套 Json 提取与解析

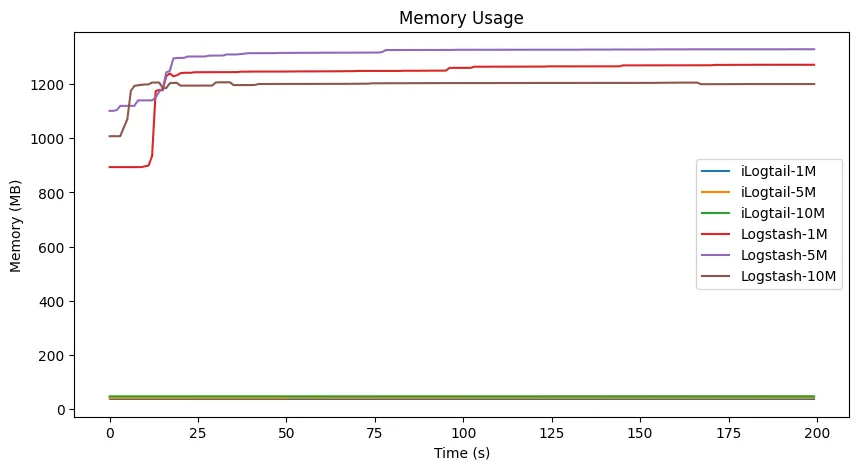
**观察:**与场景一类似,可以观察到 Logstash 的 CPU 使用率存在类似的波动。但场景三的解析处理更为复杂,所以 CPU 存在的毛刺现在也相对稀疏。
分析

从上面由简单到复杂的三个场景,我们可以分析得到一些结论:
1. 资源占用:
1. iLogtail SPL 的 CPU 和内存使用情况都远优于 Logstash。iLogtail 的平均内存 40MB 左右,最大值 50MB 左右,而 Logstash 只要启动后,就会占用 900MB 左右的内存。并且开始处理日志后,会有一个显著的增加,最大值 1250MB 左右。iLogtail 所占资源仅为 Logstash 的 5% 左右。2. 从 CPU 使用率可以看到,iLogtail SPL 在处理日志时,一直保持了比较稳定的资源使用。Logstash 的使用情况则并不是很稳定。一方面,在开始日志采集时,CPU 出现非常明显的激增。导致这个现象的原因可能有两点:一是采集延迟导致了大量日志的累积,二是启动采集所需要的初始化。另一方面,在持续的采集过程中,Logstash 的 CPU 使用情况也频繁出现波动,出现了很多毛刺现象。2. 实时性:
1. 上述的指标是在开始生成日志的同时,立刻开始监控。观察每个场景中 CPU 使用率的变化,可以发现 iLogtail 在开始后立刻发现了日志生成事件,然后开始采集日志。而 Logstash 则有比较大的延迟,在日志第一次生成后大概 10 秒左右,CPU 使用率才发生变化。2. 除此之外,我们观察场景二这类单条日志短,但数量多的场景。日志生成是在第 180 秒结束,后续的 20 秒中没有新的日志生成。iLogtail 在 180 秒左右即处理完日志,后面的 20 秒 CPU 使用率几乎为 0。但反观 Logstash,在低流量(1MB/s)的情况下,在 200 秒内还能够处理完所有的日志。但流量一旦增大(10MB/s)时,200 秒就无法处理完所有的日志了。这会导致日志采集出现较大的延迟。**3. 性能:**针对场景二的极端情况测试,可以看到 iLogtail SPL 与 Logstash Filter 能够处理的最大流量相差了 6 倍。iLogtail SPL 底层使用了 C++ 编写,利用 SIMD 等高性能计算技术,对日志数据进行并行处理。在性能和资源使用量方面都达到了很高的水平。而 Logstash 的很多 filter 插件使用了 Ruby 编写。作为一门脚本语言,其语言自身就局限了处理性能。同时,Logstash filter Ruby 插件的设计并没有很好地利用日志数据的流式特征。采用了每次只处理一条日志的设计,不能并行处理一组日志,这也是导致其性能较差的原因之一。这一点在场景二这类日志长度短但数量多的情况下,尤其突出。当然,这可以通过增加线程数来解决,但又会导致更高的资源使用量。
**4. 可拓展性:**Logstash 支持用户使用 Ruby 或者 Java 编写自定义的 filter 插件。iLogtail SPL 目前暂时不支持用户进行拓展,但在未来会支持用户通过 UDF 等方式,方便地实现满足自己需求的处理。同时,开发团队也在积极开发新的功能。除此之外,iLogtail 还提供了与 Logstash 类似的插件处理模式,支持 C++ 和 Go 语言编写。C++ 处理插件提供了更强的性能,Go 处理插件提供了更强的灵活性。
4. 结语
综上所述,iLogtail 与 Logstash 在日志处理领域的对比中,iLogtail 凭借其 SPL 处理模式展现出了显著的优势。从功能支持的角度看,虽然 Logstash 通过丰富的 filter 插件提供了广泛的功能覆盖,但在面对复杂逻辑处理、动态字段操作以及嵌套 JSON 解析等高级需求时,配置显得较为繁琐且不够直观。相比之下,iLogtail 的 SPL 不仅集成了常用的数据处理指令,还融入了 SQL 兼容性,极大地提升了配置的简洁性和可读性,降低了用户的上手难度。
在性能表现上,iLogtail 的优势更为突出。得益于 C++ 实现的核心和对 SIMD 等现代硬件特性的充分利用,iLogtail SPL 在资源占用、稳定性以及处理速度上全面超越了基于 Ruby 实现的 Logstash Filter。尤其是在高吞吐量的场景下,iLogtail 能够在较低的资源消耗下维持稳定的高性能,这对于成本敏感型企业和大规模分布式系统而言尤为重要。
综上,对于寻求高效、灵活且资源友好的日志处理方案的企业来说,iLogtail 2.0 及其 SPL 处理模式无疑是一个更具吸引力的选择。它不仅在功能上能满足多样化的日志处理需求,更在性能和易用性上设定了新的行业标准,为运维团队提供了强大的工具来应对日益增长的数据处理挑战。随着技术的不断迭代和生态的持续完善,iLogtail 希望在未来能助力企业更好地驾驭数据洪流,提升运维效率,加速数字化转型的步伐。
相关链接:
[1] iLogtail
[2] 官方文档2
[3] 官方文档3