容器内存可观测性新视角:WorkingSet 与 PageCache 监控
1. 容器工作内存 WorkingSet 概念介绍
在 Kubernetes 场景,容器内存实时使用量统计(Pod Memory),由 WorkingSet 工作内存(缩写 WSS)来表示。
WorkingSet 这个指标概念,是由 cadvisor 为容器场景定义的。
工作内存 WorkingSet 也是 Kubernetes 的调度决策判断内存资源的指标,包括节点驱逐等。
1.1 WorkingSet 计算公式
官方定义:参考 K8s 官网文档

可以由如下两个脚本在节点上运行从而直接计算结果:
CGroupV1
#!/bin/bash#!/usr/bin/env bash
# This script reproduces what the kubelet does# to calculate memory.available relative to root cgroup.
# current memory usagememory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))memory_usage_in_bytes=$(cat /sys/fs/cgroup/memory/memory.usage_in_bytes)memory_total_inactive_file=$(cat /sys/fs/cgroup/memory/memory.stat | grep total_inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];then memory_working_set=0else memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))memory_available_in_kb=$((memory_available_in_bytes / 1024))memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"echo "memory.usage_in_bytes $memory_usage_in_bytes"echo "memory.total_inactive_file $memory_total_inactive_file"echo "memory.working_set $memory_working_set"echo "memory.available_in_bytes $memory_available_in_bytes"echo "memory.available_in_kb $memory_available_in_kb"echo "memory.available_in_mb $memory_available_in_mb" #!/bin/bash
# This script reproduces what the kubelet does# to calculate memory.available relative to kubepods cgroup.
# current memory usagememory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))memory_usage_in_bytes=$(cat /sys/fs/cgroup/kubepods.slice/memory.current)memory_total_inactive_file=$(cat /sys/fs/cgroup/kubepods.slice/memory.stat | grep inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];then memory_working_set=0else memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))memory_available_in_kb=$((memory_available_in_bytes / 1024))memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"echo "memory.usage_in_bytes $memory_usage_in_bytes"echo "memory.total_inactive_file $memory_total_inactive_file"echo "memory.working_set $memory_working_set"echo "memory.available_in_bytes $memory_available_in_bytes"echo "memory.available_in_kb $memory_available_in_kb"echo "memory.available_in_mb $memory_available_in_mb"Show me the code
可以看到,节点的 WorkingSet 工作内存是 root cgroup 的 memory usage,减去 Inactve(file) 这部分的缓存。同理,Pod 中容器的 WorkingSet 工作内存,是此容器对应的 cgroup memory usage,减去了 Inactve(file) 这部分的缓存。
真实 Kubernetes 运行时的 kubelet 中,由 cadvisor 提供的这部分指标逻辑的实际代码如下:
从 cadvisor Code[1]中,可以明确看到对 WorkingSet 工作内存的定义:
The amount of working set memory, this includes recently accessed memory,dirty memory, and kernel memory. Working set is <= "usage".以及 cadvisor 对 WorkingSet 计算的具体代码实现[2]:
inactiveFileKeyName := "total_inactive_file"if cgroups.IsCgroup2UnifiedMode() { inactiveFileKeyName = "inactive_file"}workingSet := ret.Memory.Usageif v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok { if workingSet < v { workingSet = 0 } else { workingSet -= v }}2. 容器内存问题的常见用户问题 case
在 ACK 团队为海量的用户提供容器场景的服务支持过程中,很多客户在将自己的业务应用容器化部署时,或多或少都遇到过容器内存问题。ACK 团队和阿里云操作系统团队经过大量客户问题的经验沉淀,总结了以下在容器内存方面用户常见的问题:
常见问题 1:
宿主机内存使用率和容器的按节点聚合使用率数值有差距,宿主机 40% 左右,容器 90% 左右
大概率是因为容器的 Pod 算的 WorkingSet,包含 PageCache 等缓存。
宿主机的内存值,没有包含 Cache、如 PageCache、Dirty Memory 等部分,而工作内存是包含了此部分。
最常见的场景为 JAVA 应用的容器化,JAVA 应用的 Log4J,以及其非常流行的实现 Logback,默认的 Appender 会非常“简单”地开始使用 NIO 的方式,使用 mmap 的方式来使用 Dirty Memory。造成内存 Cache 的上涨,从而造成 Pod 工作内存 WorkingSet 的增长。
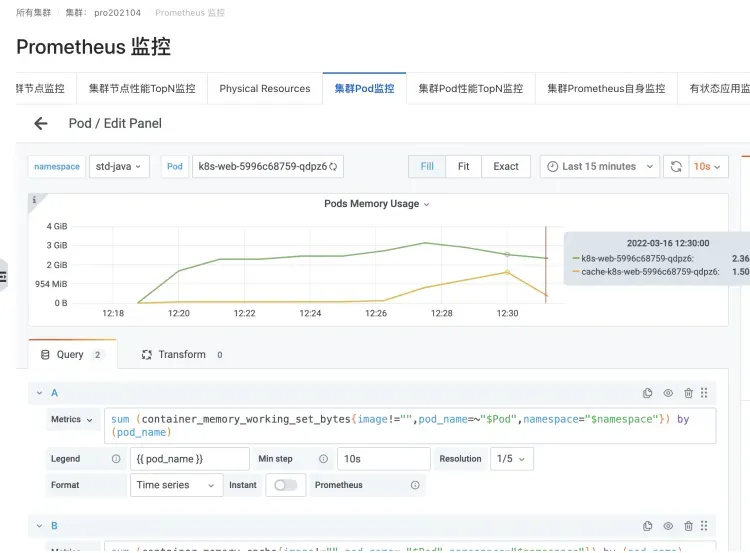
一个 JAVA 应用的 Pod 的 Logback 写日志场景
造成 Cache 内存、WorkingSet 内存上涨的实例
常见问题 2:
在 Pod 中执行 top 命令,获取到的值比 kubectl top pod 查看到的工作内存值(WorkingSet)小
在 Pod 中 exec 执行 top 命令,由于容器运行时隔离等问题,实际是突破了容器隔离,获取到了宿主机的 top 监控值。
故看到的是宿主机的内存值,没有包含 Cache、如 PageCache、Dirty Memory 等部分,而工作内存是包含了此部分,所以与常见问题 1 相似。
常见问题3:Pod 内存黑洞问题

图/Kernel Level Memory Distribution
如上图所示,Pod WorkingSet 工作内存,除了不包含 Inactive(anno),用户使用 Pod 内存的其他各成分不符合预期,都有可能最终造成 WorkingSet 工作负载升高,最终导致发生 Node Eviction 节点驱逐等现象。
如何在众多内存成分中,找到真正导致工作内存升高的真正原因,犹如黑洞一般盲目。(“内存黑洞”就是指这个问题)。
3. 如何解决 WorkingSet 高问题
通常情况下,内存回收延时都会伴随着 WorkingSet 内存使用量高出现,那么如何解决这一类问题呢?
3.1 直接扩容
容量规划(直接扩容)是解决资源高问题的通用解法。
3.2 “内存黑洞” - 深层内存成本(如 PageCache )导致怎么办
但是如内存诊断问题,需要首先剖析、洞察、分析,或者讲人话就是看清楚具体是哪块内存被谁(哪个进程、或具体哪个资源如文件)持有。然后再针对性地进行收敛优化,从而最终解决问题。
第一步:看清内存
首先怎么剖析操作系统内核级的容器监控内存指标呢?ACK 团队与操作系统团队合作推出了 **SysOM(System Observer Monitoring)**操作系统内核层的容器监控的产品功能,目前为阿里云独有;通过查看 SysOM 容器系统监控-Pod 维度中的 Pod Memory Monitor 大盘,可以洞悉 Pod 的详细内存使用分布,如下图:

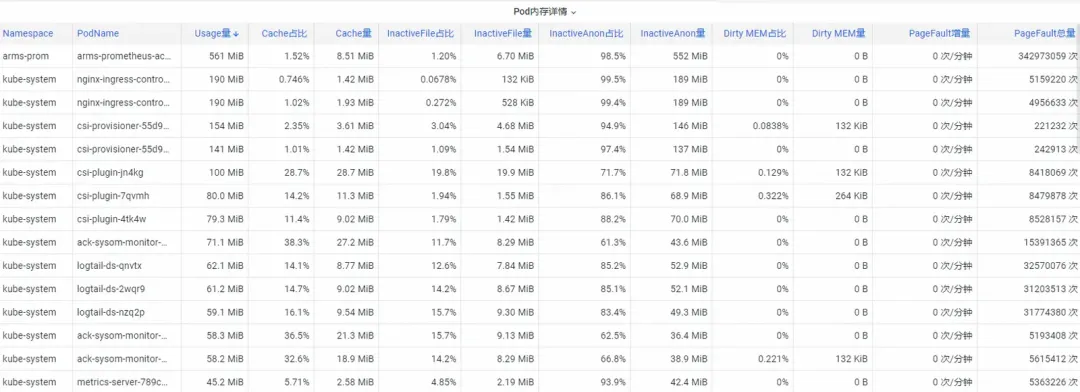
SysOM 容器系统监控能查看细粒度到每个 Pod 的详细内存组成。通过 Pod Cache(缓存内存)、InactiveFile(非活跃文件内存占用)、InactiveAnon(非活跃匿名内存占用)、Dirty Memory(系统脏内存占用)等不同内存成分的监控展示,发现常见的 Pod 内存黑洞问题。
对 Pod File Cache,可以同时监控 Pod 当前打开和已关闭文件的 PageCache 使用量(删除对应的文件就可以释放对应的 Cache 内存)。
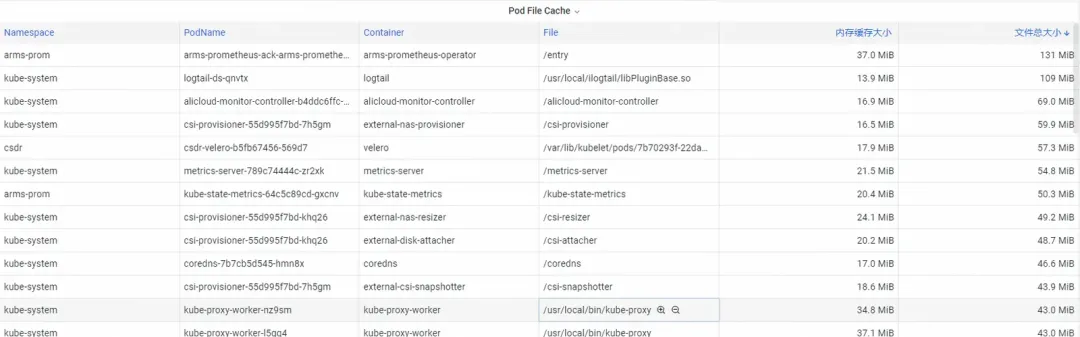
第二步:优化内存
很多深层次的内存消耗,用户就算看清了也不能轻易进行收敛,比如 PageCache 等由操作系统统一回收的内存,用户需要大费周章地侵入式改动代码,比如对 Log4J 的 Appender 加 flush(),来周期性调用 sync()。
这都是很不现实的。
ACK 容器服务团队推出** Koordinator QoS 精细化调度功能**。
实现在 Kubernetes 上,控制操作系统对内存的参数:
当集群开启了差异化 SLO 混部时,系统将优先保障延时敏感型 LS(Latency-Sensitive)Pod 的内存 QoS,延缓 LS Pod 触发整机内存回收的时机。
下图中,memory.limit_in_bytes 表示内存使用上限,memory.high 表示内存限流阈值,memory.wmark_high 表示内存后台回收阈值,memory.min 表示内存使用锁定阈值。
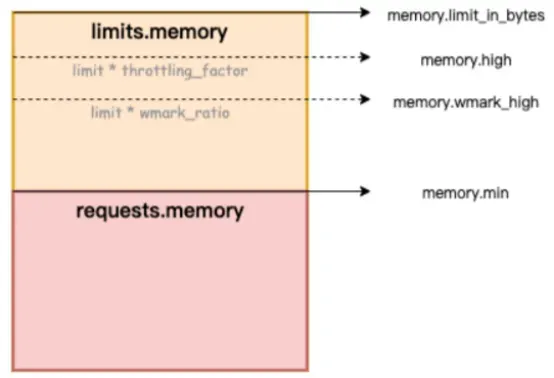
图/ack-koordinator 为容器提供内存服务质量 QoS(Quality of Service)保障能力
内存黑洞问题如何修复,阿里云容器服务通过精细化调度功能,依托 Koordinator 开源项目,ack-koordinator 为容器提供内存服务质量 QoS(Quality of Service)保障能力,在确保内存资源公平性的前提下,改善应用在运行时的内存性能。本文简介容器内存 QoS 功能,具体说明请参见容器内存 QoS[3]。
容器在使用内存时主要有以下两个方面的约束:
1)自身内存限制:当容器自身的内存(含 PageCache)接近容器上限时,会触发容器维度的内存回收,这个过程会影响容器内应用的内存申请和释放的性能。若内存申请得不到满足则会触发容器 OOM。
2)节点内存限制:当容器内存超卖(Memory Limit>Request)导致整机内存不足,会触发节点维度的全局内存回收,这个过程对性能影响较大,极端情况甚至导致整机异常。若回收不足则会挑选容器 OOM Kill。
针对上述典型的容器内存问题,ack-koordinator 提供了以下增强特性:
1)容器内存后台回收水位:当 Pod 内存使用接近 Limit 限制时,优先在后台异步回收一部分内存,缓解直接内存回收带来的性能影响。
2)容器内存锁定回收/限流水位:Pod 之间实施更公平的内存回收,整机内存资源不足时,优先从内存超用(Memory Usage>Request)的 Pod 中回收内存,避免个别 Pod 造成整机内存资源质量下降。
3)整体内存回收的差异化保障:在 BestEffort 内存超卖场景下,优先保障 Guaranteed/Burstable Pod 的内存运行质量。
关于 ACK 容器内存 QoS 启用的内核能力,详见 Alibaba Cloud Linux 的内核功能与接口概述[4]。
在通过第一步观测发现容器内存黑洞问题之后,可以结合通过 ACK 精细化调度功能针对性挑选内存敏感的 Pod 启用容器内存 QoS 功能,完成闭环修复。
参考文档:
[1] ACK SysOM 功能说明文档
[2] 最佳实践文档
[3] 中文龙蜥社区
[4] 国际站英文
相关链接:
[1] cadvisor Code
[2] cadvisor 对 WorkingSet 计算的具体代码实现
[3] 容器内存 QoS