基于Logtail的阿里云EMR日志分析链路演进
前言
阿里云 E-MapReduce (EMR) 是构建在阿里云云服务器ECS上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品。为用户提供在云上使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等场景下的大数据解决方案。目前平台对接了几十种大数据组件,每种组件都有其各自的日志文件采集需求。EMR平台的日志采用中心化采集至SLS,线上日均1 PB左右数据量。这些日志数据主要用于分析内容并产生告警事件,如何在维持功能的情况下尽可能的减少日志上传量以便降低成本是一个值得探讨的话题。
本文将对大家介绍EMR平台是如何使用 Logtail 的自定义插件在客户侧进行日志分析,避免中心侧处理海量数据。希望能对有类似需求以及类似链路架构的团队提供一定帮助。
日志分析方案演进
1.0版链路
日志通过Logtail上传到EMR服务侧SLS后,配置SLS数据加工任务写入EMR服务侧事件logstore,供后续消费。
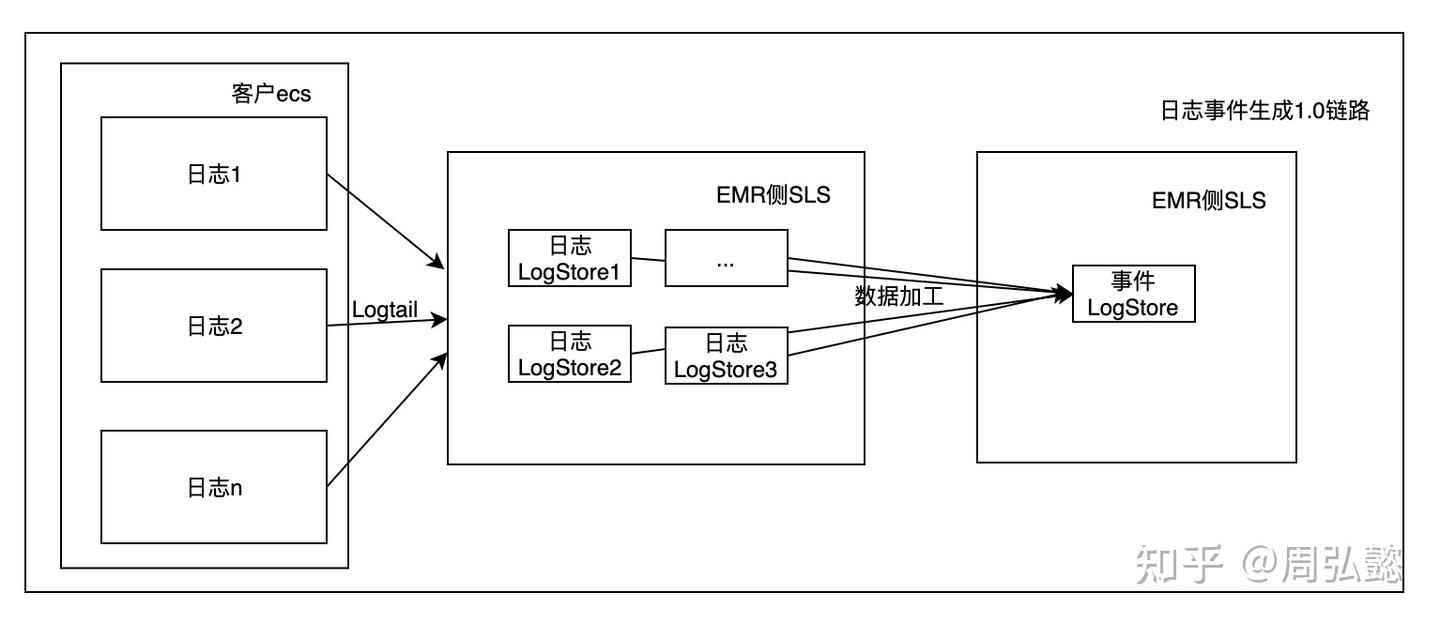
1.0版链路
2.0版链路
日志通过Logtail+日志处理插件,直接在客户侧生成事件并上传至EMR服务侧事件logstore,供后续消费。
注:若客户有意向保存完整的日志的话,EMR提供了客户侧SLS存储以及客户侧OSS存储两种。
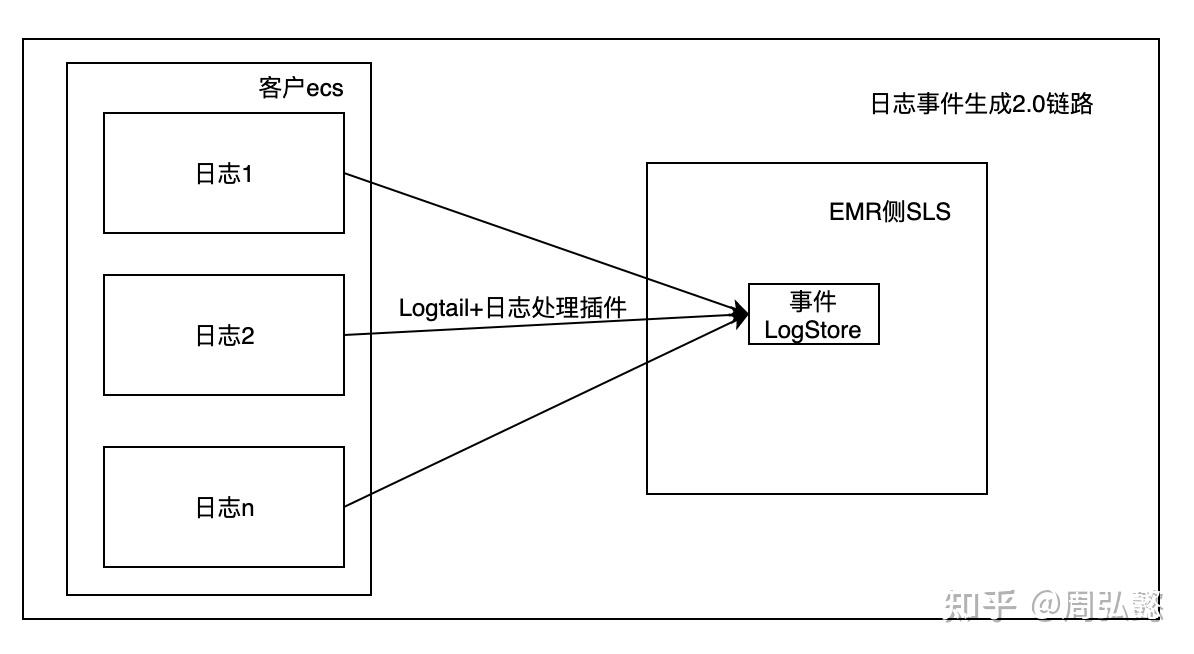
2.0版链路
1.0 VS 2.0
| 收益 | 1.0版 | 2.0版 |
|---|---|---|
| 稳定性提升 | 计算链路 长,涉及组件多,大region的logstore写入压力大 | 链路单一,减少涉及组件,logstore压力小 |
| EMR的SLS数据存储量大幅度下降,降低成本 | 所有日志数据存储在EMR的中心SLS中 | 只有核心数据(指标、巡检、事件)存储在EMR的SLS中,其他存储在客户SLS中,EMR的SLS数据量可以下降90-95% |
插件功能介绍
在1.0.34版本后,EMR团队基于Logtail的插件机制,实现了日志分析的插件processor_fields_with_condition,可以在客户侧实时分析日志生成事件。
Logtail插件介绍可参考这篇文章 Logtail插件系统简介
功能简介
processor_fields_with_condition插件支持根据日志部分字段的取值,进行模式匹配以及动态字段扩展或删除。
匹配方式:
- 可以支持多组条件(Case)进行动态字段处理,按顺序匹配上一条后即退出。
条件判断:
- 支持多字段取值比较
- 关系运算符:equals(默认)、regexp、contains、startwith
- 逻辑运算符:and(默认)、or
过滤能力:
- 默认仅做字段动态处理
- 可以开启过滤功能,未命中任意when则丢弃。
处理能力:
- 与现有插件processor_add_fields、processor_drop保持近似的使用习惯。
参数说明
如果使用社区版可以参考以下链接进行配置
配置type为processor_fields_with_condition
- detail说明如下表所示
| 参数 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| DropIfNotMatchCondition | Boolean | 否 | case条件都不满足时,该条日志是丢弃true,还是保留false(默认)。 |
| Switch | Array | 是 | 多组条件,按数组顺序匹配上一条后即退出。 |
- switch说明如下表所示
| 参数 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| Case | object | 是 | 日志匹配条件,满足后执行actions |
| Actions | Array | 是 | 匹配条件满足后执行的actions |
- case说明如下表所示
| 参数 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| LogicalOperator | string | 可选 | 多个条件之间的关系,and(默认),or |
| RelationOperator | string | 可选 | 条件识别方式,目前有相等equals(默认)、正则regexp、包含contains以及开始startwith |
| FieldConditions | map<string,string> | 必选 | 待判别字段和字段值。键值对格式,支持添加多个。 |
- action说明如下所示
目前支持processor_add_fields(添加字段)以及processor_drop(删除字段),可直接参考官方文档配置。
示例
这里对解析/var/log/messages作一个例子,根据日志中的模式生成不同告警事件,事件需要添加级别(level)以及事件码(eventcode)
在例子中,对messages文件进行了两个内容匹配与事件填充。
第一种当内容中包含 Out of memory: Kill process 就填充CRITICAL级别以及EMR-350100001事件码。
第二种当内容中包含BIOS-provided physical RAM map就填充INFO级别以及EMR-350100002事件码。
{ "global":{ "DefaultLogQueueSize":10 }, "processors":[ { "detail":{ "SplitKey":"content" }, "type":"processor_split_log_string" }, { "detail":{ "DropIfNotMatchCondition":true, "Switch":[ { "Actions":[ { "Fields":{ "eventcode":"EMR-350100001", "level":"CRITICAL" }, "type":"processor_add_fields" } ], "Case":{ "RelationOperator":"contains", "FieldConditions":{ "content":"Out of memory: Kill process" } } }, { "Actions":[ { "Fields":{ "eventcode":"EMR-350100002", "level":"INFO" }, "type":"processor_add_fields" } ], "Case":{ "RelationOperator":"contains", "FieldConditions":{ "content":"BIOS-provided physical RAM map" } } }, { "Actions":[ { "Fields":{ "eventcode":"EMR-350100003", "level":"WARN" }, "type":"processor_add_fields" } ], "Case":{ "RelationOperator":"contains", "FieldConditions":{ "content":"poweroff" } } } ] }, "type":"processor_fields_with_condition" } ]}将配置设置在SLS-Logtail配置-高级选项-插件配置处后,点击保存即可下发到机器组中各个Logtail配置上。
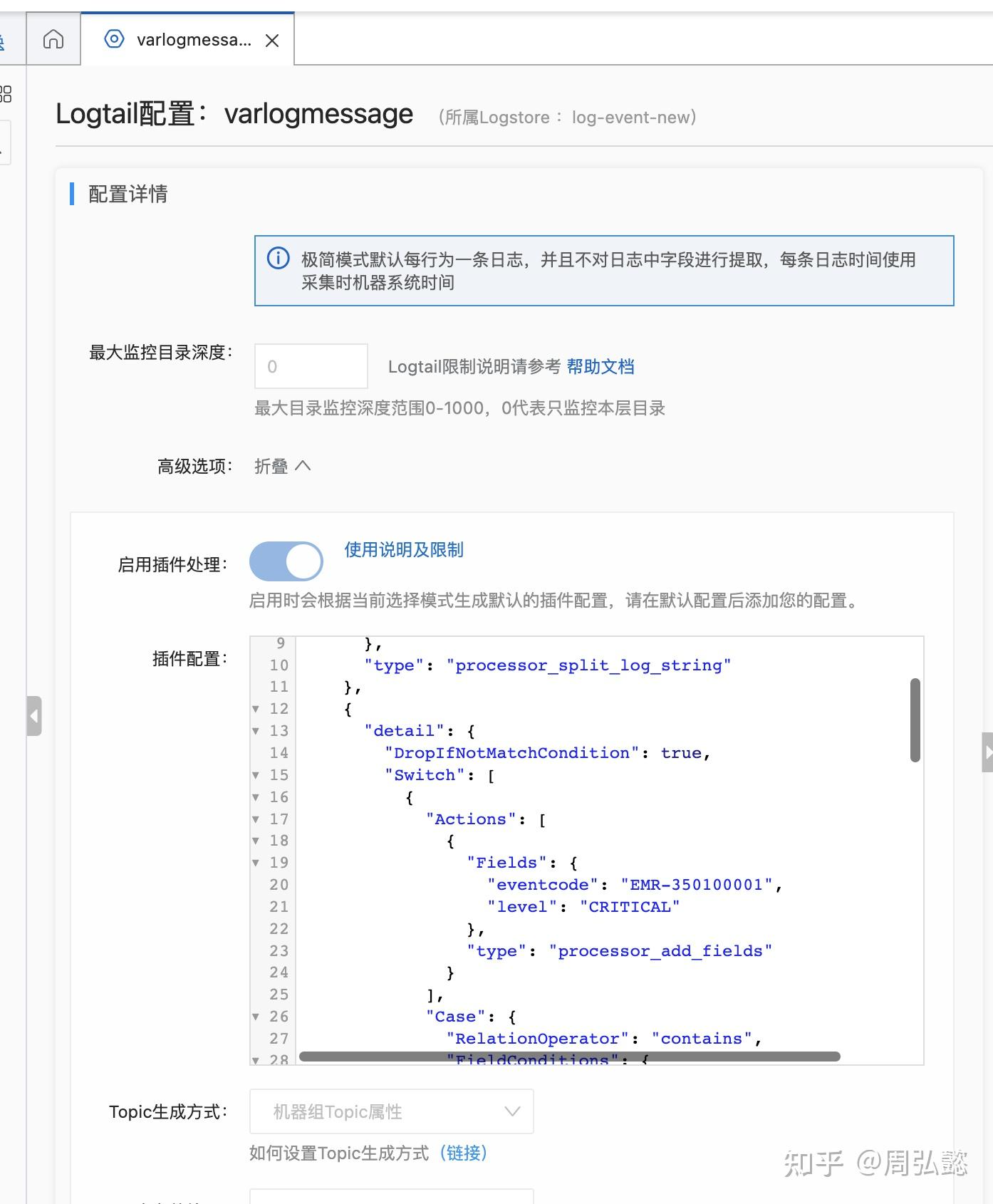
sls配置
保存后,直接可在查询界面上看到更改后的效果
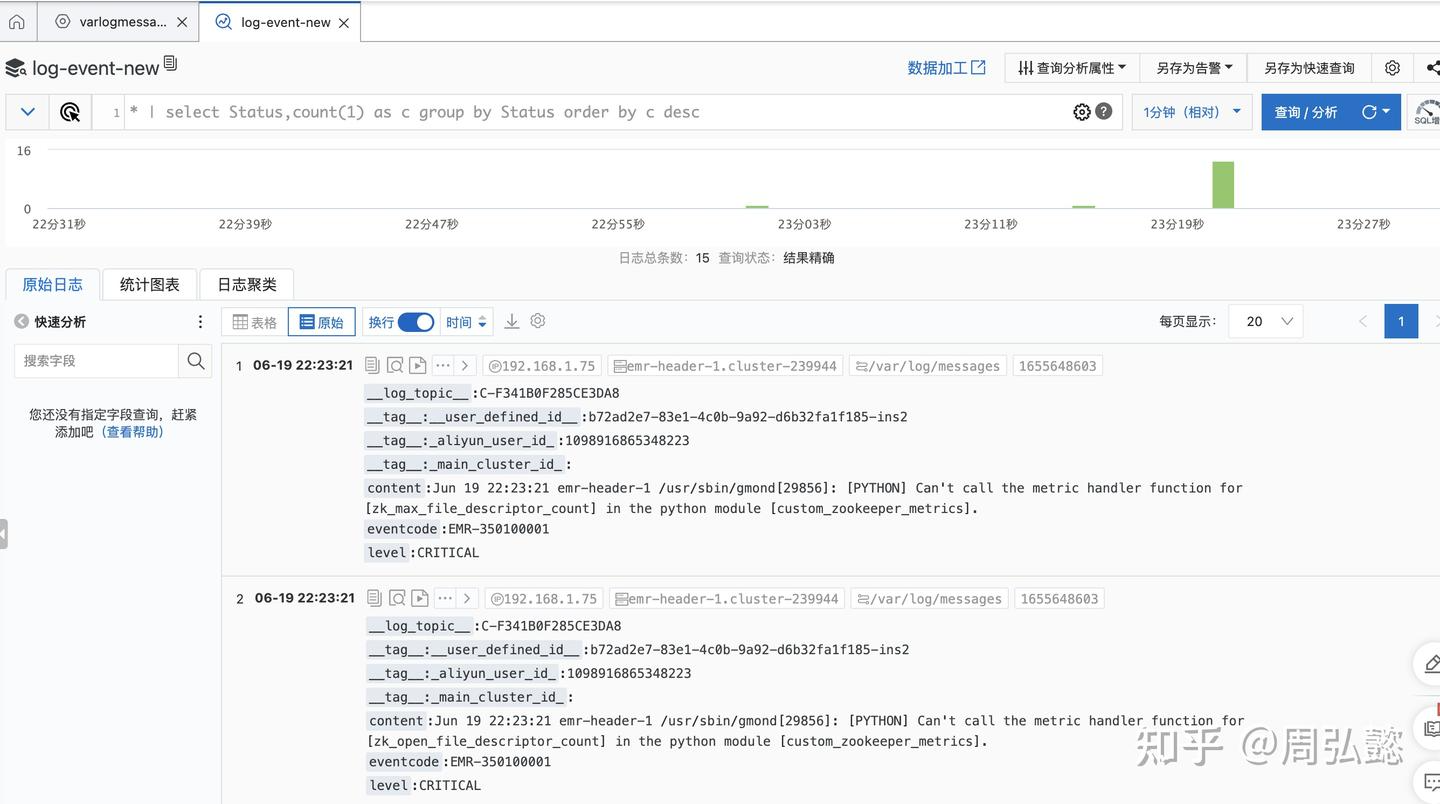
日志分析后效果
插件性能压测
测试方法采用脚本对指定目录进行速率控制的日志写入,配置采用Logtail默认的0.4core、384M限制。
测试结果为多轮测试求平均。
| 极简模式 | 开启插件(匹配一个规则) | ||
|---|---|---|---|
| 采集速度 0.1MB/s(200条/s) | cpu占用(单核) | 0.2% | 0.3% |
| 内存占用 | 0.2% | 0.2% | |
| 采集速度 1MB/s(2000条/s) | cpu占用(单核) | 1.3% | 2.5% |
| 内存占用 | 0.2% | 0.2% | |
| 采集速度 10MB/s(20000条/s) | cpu占用(单核) | 4.3% | 12% |
| 内存占用 | 0.3% | 0.3% | |
| 极限采集速度 16.5MB/s(33000条/s) | cpu占用(单核) | 7.3% | 15.7% |
| 内存占用 | 0.3% | 0.3% |
备注:测试环境
CPU :Intel (R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
MEM : 64GB
OS : Linux version 4.19.91-19.1.al7.x86_64
总结
本文介绍了一种降低成本和提高稳定性的方案,用来解决海量日志的分析需求,总结起来就是使用Logtail的插件在客户侧进行日志分析,将分析结果上传中心。