当实时消费遇到 SPL:让数据处理更高效、简单
通过 SPL 消费,将业务逻辑“左移”
SLS 对实时消费进行了功能升级,推出了 基于 SPL 的规则消费功能。在实时消费过程中,用户只需通过简单的 SPL 配置即可完成服务端的数据清洗和预处理操作。通过SPL消费可以将客户端复杂的业务逻辑“左移”到服务端,从而大幅降低了客户端的复杂性和计算开销。
核心价值:
- 低代码,可编程:SPL 提供简单的管道式可编程的语法,客户端使用低代码方式来优化数据清洗逻辑。
- 高性能:基于 SPL 消费,通过高性能计算技术在数据源头进行数据清洗和高效过滤,在不明显增加 Latency 的前提下,最大程度提升数据消费和处理效率,节省消费端计算资源。
功能优势:
- 数据精准过滤:通过 where 指令和 project 指令实现行过滤和列裁剪。
- 字符串处理:通过正则表达式进行字符串匹配和信息提取。
- JSON 数据解析:结构化日志的深度处理,通过 json 函数和 parse-json 指令解析和处理 JSON 结构化日志
- 丰富的 SQL 函数支持:SPL 兼容了大部分 SQL 函数用于数据处理,包括字符串函数、日期时间函数、JSON 函数、正则式函数、条件表达式、类型转换等。
- 复杂数据解析:数组与结构体的深度操作,支持数组函数和 MAP 映射函数和 Lambda 表达式。
典型场景下的应用
案例1:性能从 15s 到 100ms;代码从 200 行到 50 行
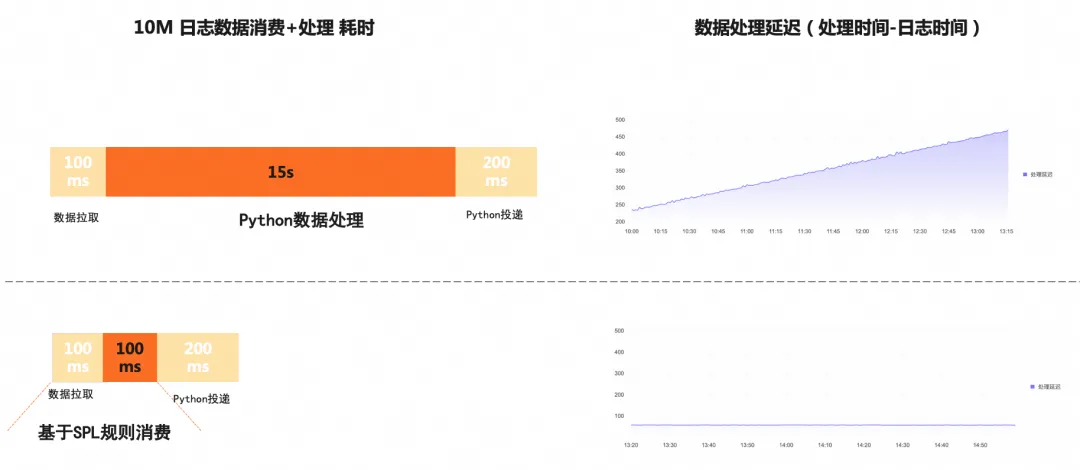
客户A使用 SLS 存储了大量应用日志,并通过 FC(函数计算) 调用 SLS 的实时消费 Python SDK 对数据进行处理。然而,在实际运行中,客户发现 Python 处理10MB日志的函数执行耗时高达 15 秒,远远超出预期,由于处理速度无法跟上日志产生的速度,处理延迟仍在不断升高,无法满足业务的实时处理需求,客户需求紧急,不希望在 Python 处理数据的流程上花费太多精力,希望能有一种低代码方式并且高性能可以满足实时处理的方式来快速上线功能。
经过深入排查,问题根源在于客户的实时消费程序中包含了复杂的本地数据处理逻辑(约 200 行 Python 代码),例如正则表达式提取、JSON 格式转换等操作。加上对 Python 数据处理性能调优的经验不足,导致整体处理效率较低。
针对这一问题,SLS 推荐客户采用基于 SPL 规则消费 的方式,将数据处理流程做了如下简化,将 Python 代码中的数据清洗逻辑,转换为 SPL 并配置在消费程序中,删除了大量的低效的数据处理逻辑,替换为简洁高效的 SPL(约 50 行)。

通过在 Python 消费程序中配置 SPL,将复杂的数据清洗和预处理任务下推到服务端完成。服务端返回的结果已经是经过清洗和格式化的数据,客户端无需再进行复杂的本地处理。最终,通过在实时消费中引入 SPL,客户的 10MB 日志函数处理耗时从 15 秒 降低至 不到 100 毫秒,显著提升了处理效率。下图展示了使用基于 SPL 规则消费代替 Python 数据清洗逻辑的原理及数据处理延迟对比。
基于 SPL 规则消费给客户带来价值:
- 业务解耦,低代码降低数据清洗门槛
SPL 语法简洁直观,学习成本低且调试便捷,相较于使用多种编程语言或平台实现数据清洗逻辑,低代码的方式开发难度显著降低。通过将数据清洗任务交给规则消费功能,实现业务逻辑与数据处理的高效解耦。客户实时处理需求响应从天/小时级提高到分钟级。
- 节省本地计算资源,加速处理效率
通过将数据在服务端过滤,无需依赖本地资源进行复杂处理。这不仅显著降低了本地 CPU 的消耗,还大幅提升了整体计算效率。
案例2:计算下推:带宽减少 90%,客户端计算资源减负
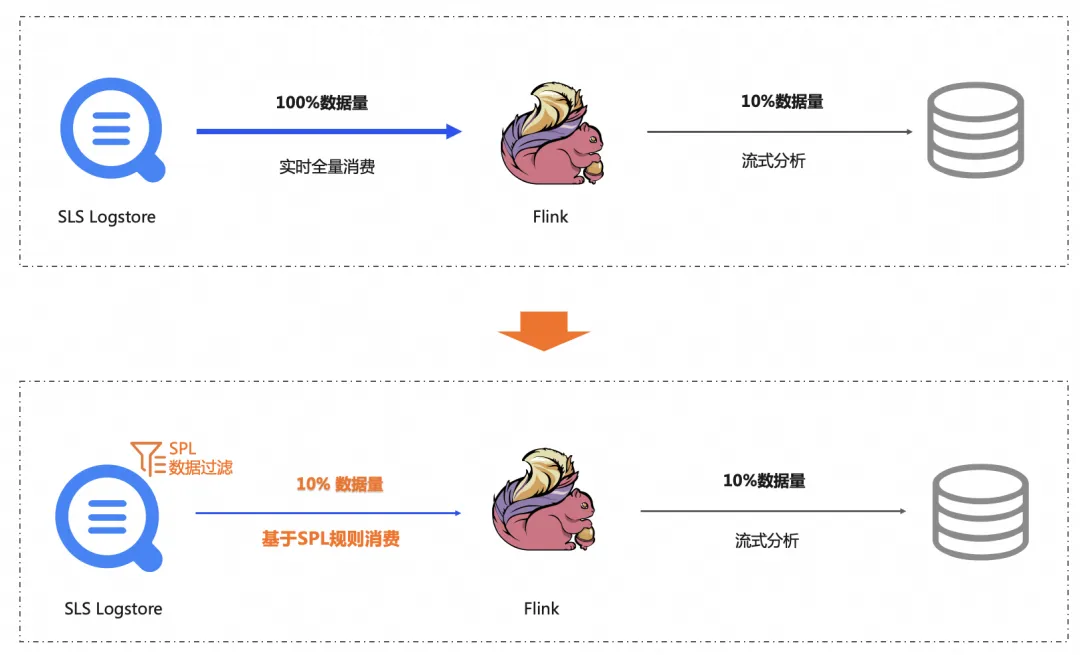
客户B在 日志服务 多个地域的 Logstore 中存储了数据库审计日志,并使用特定地域的阿里云 Flink 进行数据分析和流计算,通过 Flink SLS Connector 将数据拉取到 Flink 中进行流式聚合分析,客户发现对于日志的处理延迟非常高,期望可以实时对产生的日志进行流式处理,最好可以降低跨地域拉取产生的公网带宽费用。同时,也会使用 Flink 对于历史的日志进行分析,在处理历史数据时耗时较长
支持中发现:客户的需求是对跨地域的部分数据库实例的日志进行分析,这些日志仅占全量日志的 10%。客户使用 Flink SLS Connector ,将 Logstore 的全量拉取到 Flink 端。也就是说,跨地域访问的场景中,90%公网的流量是不必要的开销,同时这 90% 的数据到达 Flink 端也会增加状态存储和计算负担,由于源日志数据仍在快速产生,但是客户所在环境公网带宽有限,加剧了拉取日志的延迟,在分析历史数据时,处理耗时更长。
经过分析:SLS 推荐用户在 Flink SLS Connector 中配置简单的SPL过滤语句,实现数据的过滤下推,在过滤下推后,只有用户需要的 10% 的数据从 SLS 传递到 Flink 端,数据量的大幅度减少,分析相同的数据量只需要更少的时间,除此之外,还节省了 90% 的公网流量费用,为客户实现了降本增效。
基于 SPL 规则消费给客户带来的价值:
- 公网消费,显著节省流量费用
基于 SPL 规则消费功能,可以直接在日志服务中完成规则过滤,避免将大量无效日志传输到消费端,在跨地域消费场景中,大幅减少公网流量的使用,降低流量成本。
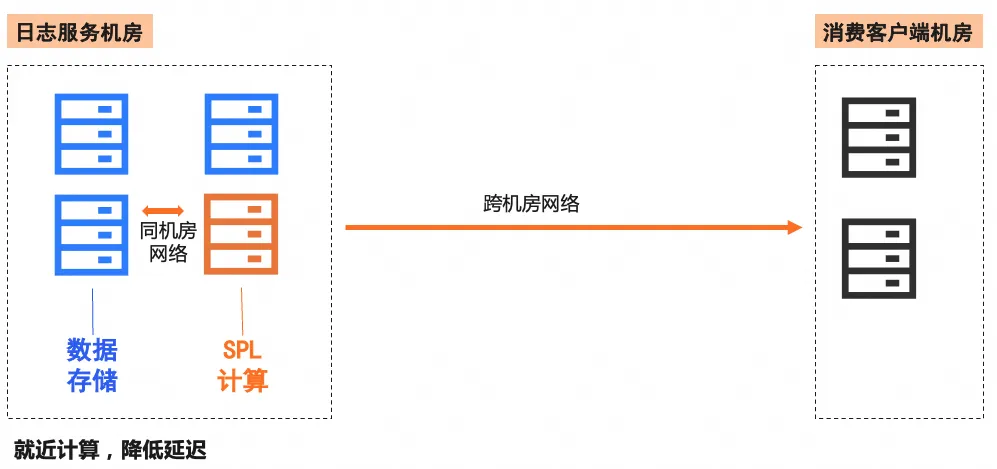
同时,SPL 规则计算服务与日志存储服务在同机房部署,即使在非公网条件下,也可以在极低的网络延迟下就近计算来提高计算性能。
- 稳定性增强、减少本地计算量
通过 Flink SLS Connector 的过滤下推,在依赖状态的流计算的作业场景中,可以显著减少本地计算的数据量,同时可以降低本地状态存储,增强系统的稳定性。
生态集成与展望
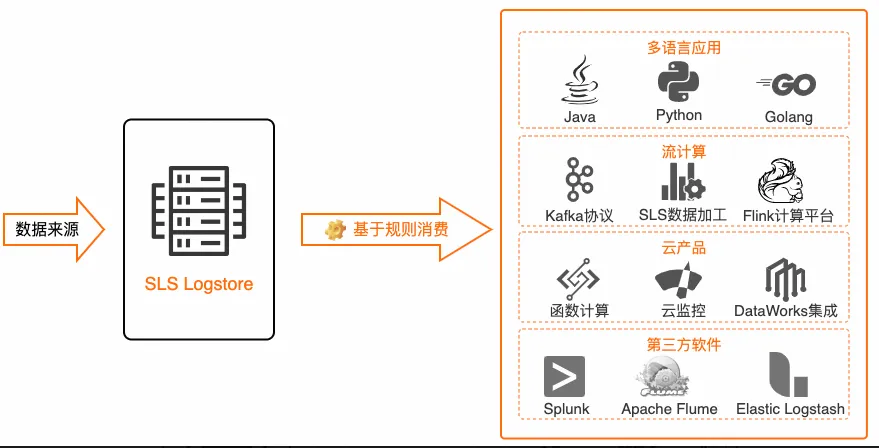
当前 SLS 基于规则消费已经与阿里云 Flink、Dataworks、Splunk、FunctionCompute 等数据日志消费类产品完成对接,在对应平台上可以无缝使用 SPL 进行日志数据的预处理,将处理清洗后的数据交给云产品进行数据分析。同时,SLS 的多语言 SDK 包括 Java、Python、Golang 等已完成基于规则消费的适配,实时消费接口与消费组接口可以直接配置 SPL 进行日志数据预处理。
已支持集成生态
- 阿里云 Flink 接入 SPL 实践:
- 阿里云 Flink SLS 连接器(支持 SPL)【1】
- 阿里云 Flink SQL 基于 SPL 实现行过滤【2】
- 阿里云 Flink SQL 基于 SPL 实现列裁剪【3】
- 阿里云 Flink SQL 基于 SPL 实现弱结构化分析【4】
- Dataworks 接入 SPL 实践:
- Dataworks 数据集成-SLS 数据源(支持 SPL)【5】
- Splunk HEC 接入 SPL 实践:
- Splunk HEC 投递日志到 SIEM(支持 SPL)【6】
- 多语言基于 SPL 规则消费最佳实践:
- 使用 Java SDK 基于 SPL 消费【7】
- 使用 Java 消费组基于 SPL 消费日志【8】
- 使用 Go SDK 基于 SPL 消费日志【9】
- 使用 Go 消费组基于 SPL 消费日志【10】
- 使用 Python SDK 基于 SPL 消费日志【11】
- 使用 Python 消费组基于 SPL 消费日志【12】
待集成生态
在日志消费处理场景,会对更多开源及三方生态进行基于 SPL 消费的支持,包括不限于:
- Flume 基于 SPL 消费 SLS 日志
- Logstash 基于 SPL 消费 SLS 日志
- 更多生态集成中…
展望
- SPL Processor 集成:随着用户将更多的数据清洗逻辑通过 SPL 左移到存储层,SPL 会放开更长的语句限制,同时支持将 SPL 语句存储在 SPL Processor 中,在实时消费时仅需指定对应的 processorId 即可实现 SPL 消费,在配置消费时,简化了 SPL 长语句的书写和代码复用。
- 持续性能提升:过滤操作在数据清洗场景中占有很重要的比例,不仅可以节省网络延迟和流量,同时可以减少下游的计算量,我们将针对过滤场景进行深度优化,将过滤场景实时消费 Latency 再降 50%。
相关链接:
【4】阿里云 Flink SQL 基于 SPL 实现弱结构化分析
【5】Dataworks 数据集成-SLS 数据源(支持 SPL)